
La sauvegarde de vos bases de données est un point crucial de votre stratégie de PRA.
L’actualité récente a montré combien il était important de suivre la règle des 3-2-1 en matière de backups. 3 copies de vos données à minima dont les données de production et au moins 2 backups si possible stockés sur des média distincts (ou des baies distinctes) et au moins une sauvegarde externalisée. Car en cas de sinistre majeur sur votre datacenter principal, il est tout à fait plausible que vos sauvegardes soient également impactées. D’où l’utilité de la sauvegarde externalisée.
Autre point non négligeable à prendre en compte : les fameux cryptolockers ou ransomware qui fleurissent en ce moment. Comment se protéger contre ce risque, car un simple backup sur une baie accessible via un partage réseau laisse planer le risque… Et ce n’est pas la recopie à postériori de vos backups sur un second stockage qui vous solutionnera le problème car, potentiellement, dès le backup terminé, le handle sur le fichier est levé et donc le cryptolocker peut agir. Le fichier que vous recopierez sera alors déjà corrompu.
Compliqué donc de se sortir de cette situation a moins d’aborder la notion de stockage immuable pour vos backups. La version 11 de VEEAM de mémoire propose ce genre de choses, mais cela veut dire utiliser un outil tiers pour gérer ses sauvegardes, et j’avoue ne pas y être favorable. Avec près de 25 ans de SQL au compteur (cela remonte à 1997 pour être exact), bien des éditeurs m’ont fait les yeux doux en essayant de m’expliquer (ou en criant très fort) que c’était vraiment beaucoup mieux, mais non, désolé. Une fois votre solution en place, en tant que DBA je ne suis plus libre de mettre en place mes Log Shipping, relancer des backups pour mettre en place des groupes de disponibilité (avant l’apparition de l’auto-seeding), sans compter avec les gros Fail rencontrés sur des scénarios de restaure moins conventionnels et les schedulers fainéants qui rechignent à planifier du backup log fréquemment au risque de faire exploser des journaux de transactions… Bref très peu pour moi. Seule la partie VDI me semble viable, mais je perds beaucoup de maitrise.
Comment donc solutionner ce problème. J’avoue que la solution Azure, au travers des blobs offre l’avantage d’un accès via une URL HTTPS, avec un jeton d’accès à durée limité (je parle de block blob et pas de page blob), et un credential positionné dans SQL Server. Pas de partage réseau, donc beaucoup moins de risque !
Je ne vais pas aborder en détail ici la partie mise en place, les best practices, et les différences entre page et block blogs, ce n’est pas le propos.
Le but de cet article est d’aborder la rétention des fichiers. Comment supprimer les « vieux » backups, ceux qui ont dépassé la durée de rétention.
Les conteneurs, partie intégrante des comptes de stockage, proposent plusieurs solutions, donc certaines extrêmement simples à mettre en place.
Le plus simple consisterait à utiliser la notion de Life Cycle Management. Qui de plus naturel que de spécifier une durée de rétention et ensuite de laisser Azure supprimer automatiquement les fichiers …

Tout comme l’utilisation d’un Runbook, planifié tous les jours par exemple qui purgerait les fichiers antérieurs à notre rétention.
Mais ces deux solutions sont imparfaites à mon sens, car elles ne satisfont pas à la règle des 3-2-1. Imaginons par exemple que des sauvegardes échouent pour une raisons quelconque et que personne n’y prête attention (ne rigolez pas j’ai vu des jobs en erreur durant plus d’un an …). Votre conteneur serait alors totalement vide, puis que l’exécution de la purge n’est pas liée à l’arrivée d’un nouveau fichier.
On peut conserver le runbook pour le côté exécution de la tâche, mais pour le déclanchement, je vous propose d’utiliser la notion d’évènement : dès qu’un fichier de backup est écrit dans le conteneur, alors, une fois la sauvegarde terminée, on peut purger …
Exemple : un backup database (.bak) est déposé, on peut purger le .bak de cette base de données datant de plus de x jours. Idem pour les backups log et backup différentiels.
C’est donc ce scénario que je vous propose d’explorer dans cet article, dont les grandes étapes vont être :
– Création du compte de stockage et du conteneur
– Création du Runbook à base de PowerShell
– Configuration d’un WebHook pour lancer l’exécution du runbook.
– Création d’un Eventgrid topic
– Abonnement à l’évènement de création de fichier et appel au WebHook
Il existe un tout petit préalable pour faire fonctionner la solution : enregistrer EventGrid dans votre abonnement. Cette ressource est à la base de « tout » Azure, mais pour pouvoir l’utiliser, vous devez l’ajouter à votre abonnement. A faire une et une seule fois …
Rendez-vous dans votre abonnement, sélectionnez l’item Resource Provider, faites la recherche EventGrid et ensuite il n’y a plus qu’à cliquer sur Register.
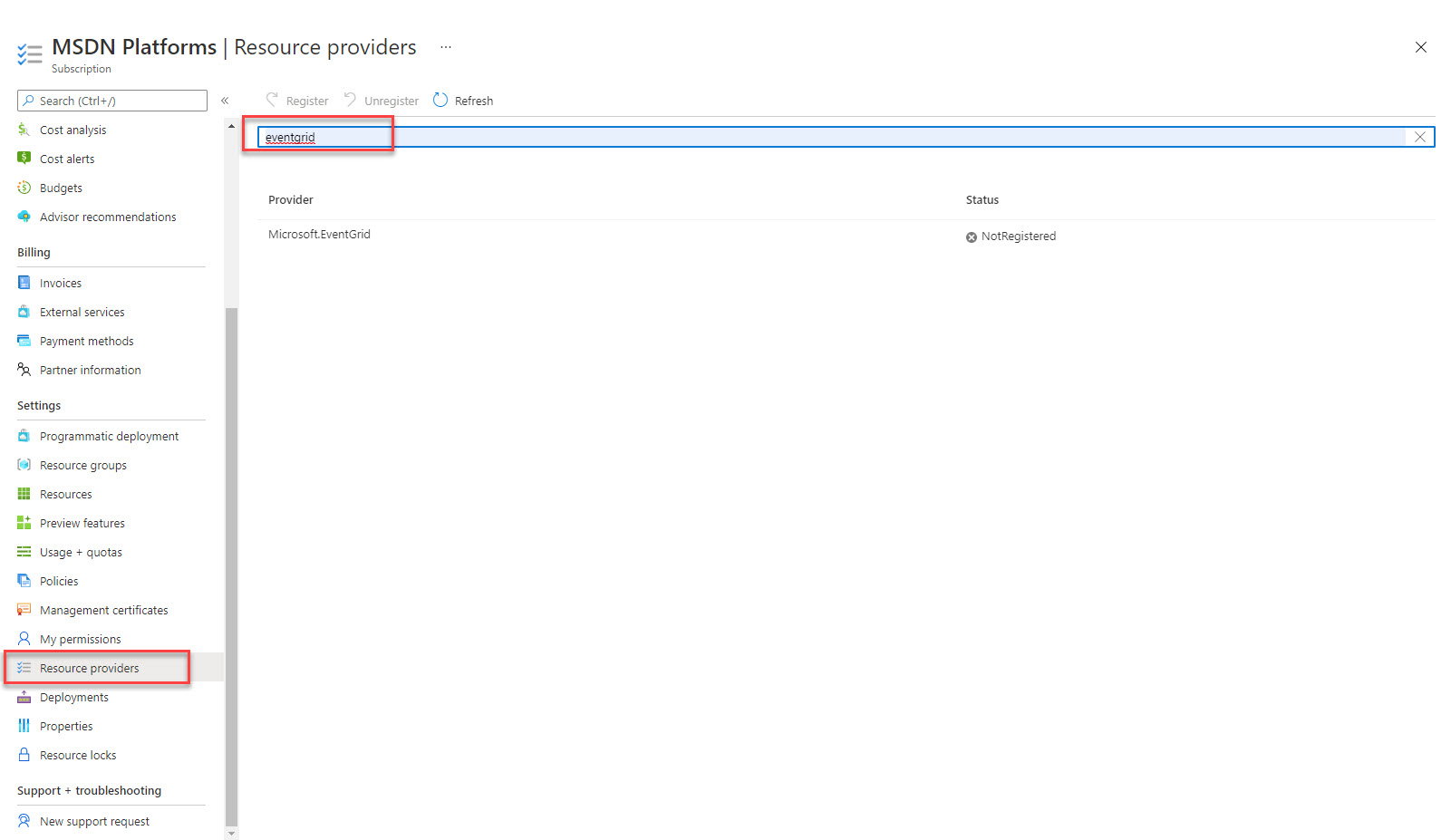
L’opération n’est pas instantanée, mais cela ne nous empêche pas de continuer avec la création d’un storage account.
Le propos n’est pas ici de discuter des différences entre un tiers Chaud ou un tiers Froid, vu la différence de cout au TB et à la latence induite par le tiers froid en matière de restaure, tout comme les pénalités en cas de suppression anticipée, j’ai ici opté pour un tiers chaud, en mode RA-GRS.
Si vous avez suivi le propos en introduction, utiliser une réplication LRS (locally Redundant Storage) ne fait pas sens pour du backup de données critiques pour l’entreprise. Eventuellement, opter pour une réplication ZRS (Zone Redundant Storage) pourrait s’entendre, mais vu la différence ce prix, autant opter pour une réplication GRS (Geo-Redundant Storage), qui si vous travaillez un peu avec Azure SQL Databases ou les Managed Instances, constituent l’option par défaut inclue dans le prix. Ne doutons pas un seul instant qu’il s’agisse de la solution la mieux adaptée à notre cas de figure. La redondance GZRS ne nous apporte rien, mais par contre l’option RA (Read-Access) parait couler de source. Optons donc pour RA-GRS …
La création du compte de stockage ne pose pas de problème particulier. Ce qui me dérange le plus c’est de ne pas pouvoir appliquer ma convention de nommage comme je peux le faire sur les autres ressources Azure. 😦

Les options des différents onglets de l’assistant sont laissées telles quelles. Une fois le compte de stockage créé, cela peut prendre une minute ou deux, il suffit de créer un conteneur afin de supporter nos fichiers. Notez qu’il est possible de créer plusieurs containers, pour ma part j’ai souvent « sql-backup », « sql-backpac », « sql-audit », « sql-xevent » et « sql-bulk ». Cela couvre une grande majorité de mes besoins. Le nom que vous allez donner à cotre conteneur va recouvrir une certaine importance dans le filtrage des évènements, car il n’est pas question de purger des fichiers d’audit lorsque nous en créons un nouveau. Ou même de supprimer un fichier xEvent lorsqu’un backup est créé.
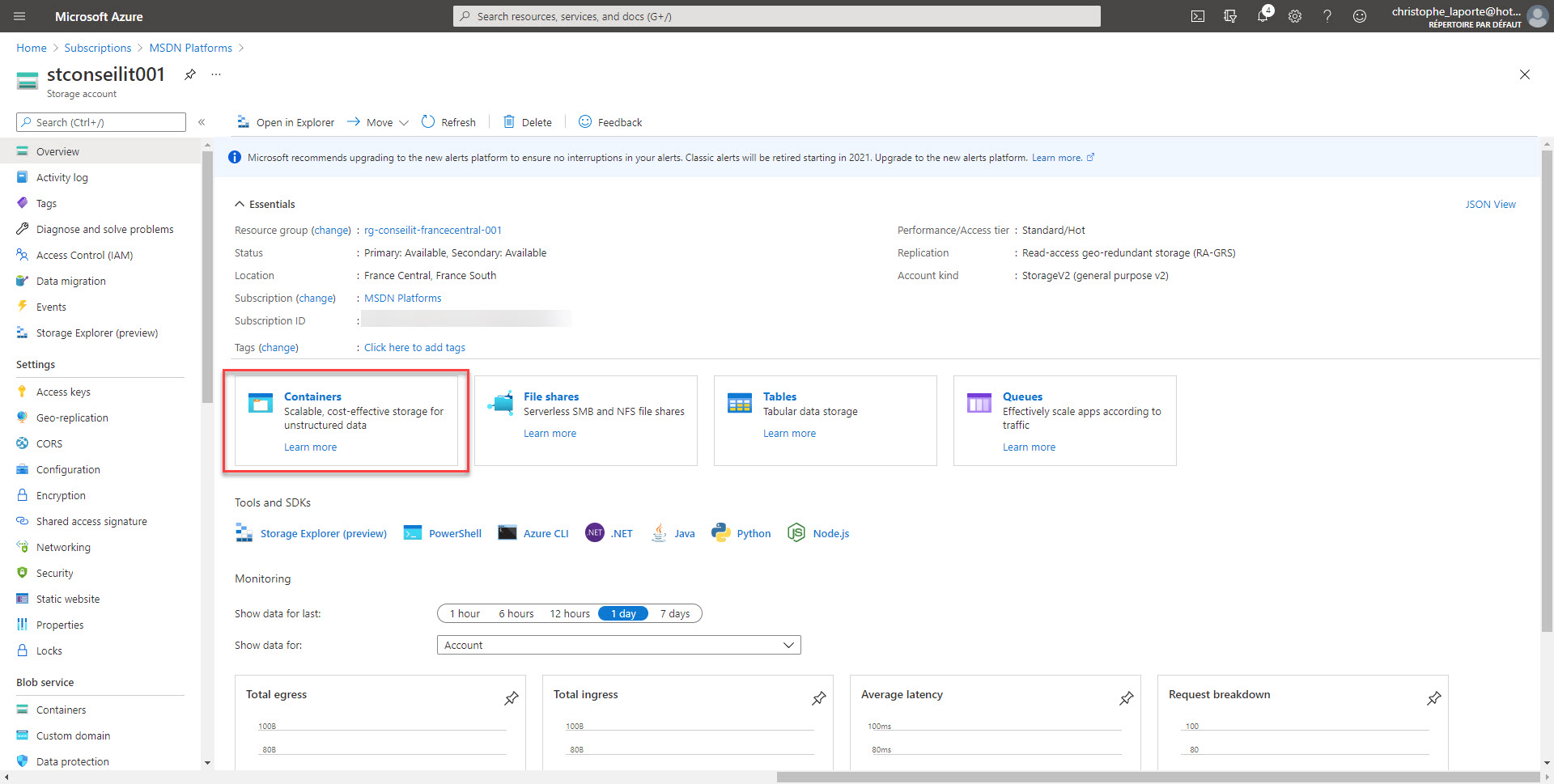

Ensuite, la création d’un RunBook nécessite la présence d’un compte d’automatisation, dont la création ne requiert pas d’attention particulière.

Vous noterez au passage que 3 Runbooks ont été créé par défaut, ce sont des exemples que vous pouvez bien entendu supprimer.

Il suffit ensuite d’aller sur le compte d’automation et de créer un RunBook

Afin de rendre le système relativement générique, j’ai opté pour 3 variables, chacune relative à la rétention de chaque type de sauvegarde : Complète, Différentielle et Journaux de transaction.

Une fois fait, nous pouvons passer à la partie création du Runbook de type Powershell.

Et d’ajouter du code afin d’effectuer les travaux de purge de fichiers.

Procédez ensuite à la sauvegarde et à la publication du code, ce qui le rendra exploitable.
Mais revenons quelques instants sur ce bout de code pour éviter un bête copier/coller sur votre environnement.
En premier lieu, nous trouvons un paramètre de type Object, sérialisé en JSON et qui va décrire l’évènement (n’oubliez pas que ce RunBook sera appelé via un EventGrid et un Topic d’ajout de nouveau fichier sur le Container).
Voilà à quoi pourrait ressembler le document JSON :
{
"WebhookName": "webhook-purge-old-backup-files",
"RequestBody": "[{\"topic\":\"/subscriptions/xxxxxx/resourceGroups/rg-conseilit-francecentral-001/providers/Microsoft.Storage/storageAccounts/stconseilit001\",\"subject\":\"/blobServices/default/containers/sql-backup/blobs/SQL2019/master/FULL/SQL2019_master_FULL_20210416_082843.bak\",\"eventType\":\"Microsoft.Storage.BlobCreated\",\"id\":\"75ed5bed-001e-004f-7689-32ff72063bfa\",\"data\":{\"api\":\"PutBlockList\",\"requestId\":\"75ed5bed-001e-004f-7689-32ff72000000\",\"eTag\":\"0x8D900A0EBC3D5E4\",\"contentType\":\"application/octet-stream\",\"contentLength\":1179648,\"blobType\":\"BlockBlob\",\"url\":\"https://stconseilit001.blob.core.windows.net/sql-backup/SQL2019/master/FULL/SQL2019_master_FULL_20210416_082843.bak\",\"sequencer\":\"0000000000000000000000000000247900000000000ba5ec\",\"storageDiagnostics\":{\"batchId\":\"9c08ea16-3006-0054-0089-32c171000000\"}},\"dataVersion\":\"\",\"metadataVersion\":\"1\",\"eventTime\":\"2021-04-16T06:28:59.9893243Z\"}]",
"RequestHeader": {
"Connection": "close",
"Accept-Encoding": "gzip",
"Host": "xxxxxxxxxxxxxxxxxxxxxxxxxx.ab.webhook.fc.azure-automation.net",
"aeg-subscription-name": "SUBSCRIPTION-PURGE-DELETE-BACKUP-FILES",
"aeg-delivery-count": "0",
"aeg-data-version": "",
"aeg-metadata-version": "1",
"aeg-event-type": "Notification",
"x-ms-request-id": "d921eef1-3d32-45fc-8953-659374135ffb"
}
}
La partie la plus intéressante transmise est contenue dans la balise URL :
« url\ »:\ »https://stconseilit001.blob.core.windows.net/sql-backup/SQL2019/master/FULL/SQL2019_master_FULL_20210416_082843.bak\ »
L’idée consiste alors à analyser cette URL qui caractérise totalement le travail que nous devrons réaliser dans le code PowerShell pour purger les backups de la base Instance et base. Tout d’abord, sachez que les backups sont réalisés au travers de la solution de maintenance écrite par Ola Hallengren et dont j’ai déjà eu l’occasion de présenter que ce soit dans ce blog ou au travers de mes vidéos consacrées aux dbaTools. Et cela va nous faciliter la tâche car une structure de dossiers et sous dossiers va automatiquement être créée dans le container.

L’URL contient donc les informations du Container, de l’instance SQL, de la base et du type de backup. Il ne reste alors qu’à extraire ces informations.
$url = "https://stconseilit001.blob.core.windows.net/sql-backup/SQL2019/master/FULL/SQL2019_master_FULL_20210416_082843.bak\"
$storageContainerName = (($url).split("/")[3])
$storageAccountName = (($url).split("/")[2]).split(".")[0]
$storagePrefixName = ($url).split("/")[4..(($url).split("/").Count-2)] -join("/")
$backupType = ($url).split("/")[($url).split("/").Count-2]
write-output "Account : $storageAccountName"
write-output "Container : $storageContainerName"
write-output "Prefix : $storagePrefixName"
write-output "Backup type : $backupType"

La notion de préfixe revêt toute son importance car il s’agit tout simplement du « répertoire » dans lequel nous devons effectuer la purge de fichier. Dans notre cas, une sauvegarde FULL sur la base Master de l’instance SQL2019.
Maintenant que nous avons accès au type de sauvegarde, nous recherchons dans les variables créées précédemment sur le compte d’automatisation quelle est la durée de rétention qui s’applique et calculons la date d’ancienneté maximale :
switch ($backupType)
{
"FULL" { $backupRetention = $(Get-AutomationVariable -Name 'fullBackupRentionInDays') }
"DIFF" { $backupRetention = $(Get-AutomationVariable -Name 'diffBackupRentionInDays') }
"LOG" { $backupRetention = $(Get-AutomationVariable -Name 'logBackupRentionInDays') }
}
$CleanupTime = [DateTime]::UtcNow.AddHours(- $backupRetention)
Enfin, nous récupérons le contexte de stockage, recherchons tous les fichiers antérieurs à la date d’ancienneté maximale dans le « répertoire » en question avant d’afficher les fichiers correspondant au critère et de les supprimer (en fonction du booléen).
$context = New-AzureStorageContext -StorageAccountName $storageAccountName -StorageAccountKey "xxxxxxxxxxxxxxxxxxxxxxxxxx"
$blogsToDelete = Get-AzureStorageBlob -Container $storageContainerName -prefix $storagePrefixName -Context $context | Where-Object { $_.LastModified.UtcDateTime -lt $CleanupTime }
$blogsToDelete | Select-Object Name,LastModified | sort-object LastModified -descending | Format-Table -autosize
if ($performDelete){
$blogsToDelete | Remove-AzureStorageBlob
}
Ce qui nous donne un script complet :
param
(
[Parameter (Mandatory = $false)]
[Object] $WebHookData
)
$performDelete = $false
if ($WebHookData) {
$WebHookData = ConvertFrom-Json $WebHookData
$body = (ConvertFrom-Json -InputObject $WebHookData.RequestBody)
$storageContainerName = (($body.data.url).split("/")[3])
$storageAccountName = (($body.data.url).split("/")[2]).split(".")[0]
$storagePrefixName = ($body.data.url).split("/")[4..(($body.data.url).split("/").Count-2)] -join("/")
$backupType = ($body.data.url).split("/")[($body.data.url).split("/").Count-2]
switch ($backupType)
{
"FULL" { $backupRetention = $(Get-AutomationVariable -Name 'fullBackupRentionInDays') }
"DIFF" { $backupRetention = $(Get-AutomationVariable -Name 'diffBackupRentionInDays') }
"LOG" { $backupRetention = $(Get-AutomationVariable -Name 'logBackupRentionInDays') }
}
$CleanupTime = [DateTime]::UtcNow.AddHours(- $backupRetention)
write-output "Event time : $($body.eventTime)"
write-output "Subject : $($body.subject)"
write-output "Blob URL : $($body.data.url)"
write-output "Account : $storageAccountName"
write-output "Container : $storageContainerName"
write-output "Prefix : $storagePrefixName"
write-output "Backup type : $backupType"
write-output "Retenion : $backupRetention"
write-output "Delete prior : $CleanupTime "
$context = New-AzureStorageContext -StorageAccountName $storageAccountName -StorageAccountKey "xxxxxxxxxxxxxxxxxx"
$blogsToDelete = Get-AzureStorageBlob -Container $storageContainerName -prefix $storagePrefixName -Context $context | Where-Object { $_.LastModified.UtcDateTime -lt $CleanupTime }
$blogsToDelete | Select-Object Name,LastModified | sort-object LastModified -descending | Format-Table -autosize
if ($performDelete){
$blogsToDelete | Remove-AzureStorageBlob
}
}
Tout est donc prêt à présent pour l’exécution de la purge, il reste à se préoccuper du déclanchement des opérations.
Pour ce faire nous allons créer un WebHook sur le RunBook. Pensez à copier l’URL du WebHook car pour des raisons de sécurité, pour ne pourrez plus y accéder une fois créée. Il s’agit là de sa seule protection …
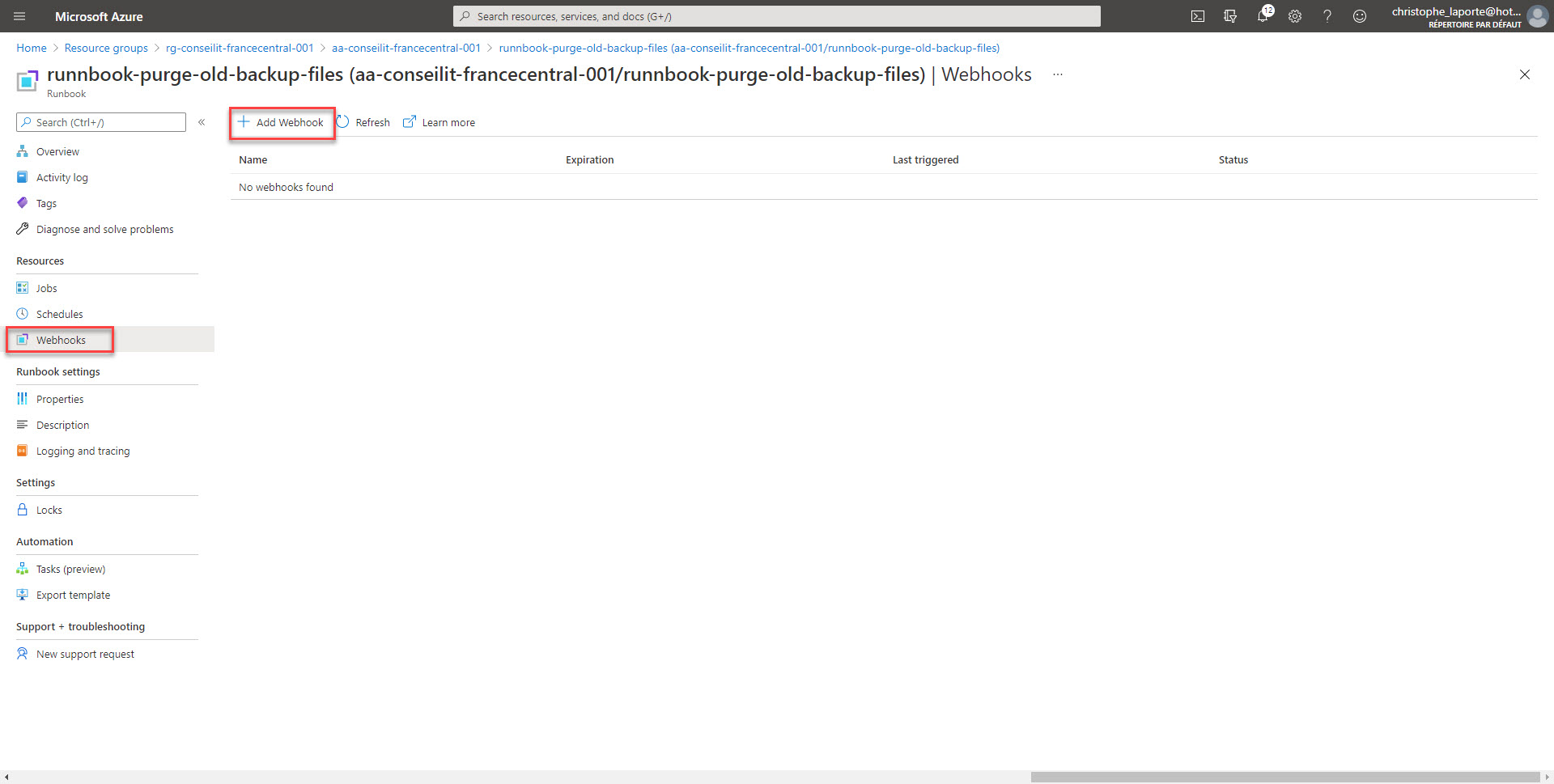

Attention à la durée limite d’utilisation également !!! Allez ensuite sur l’onglet paramètres, il n’est pas nécessaire de mettre une valeur pour le paramètre WebHookData mais c’est obligatoire de valider (par le OK) cette étape dans le process de création du WebHook.

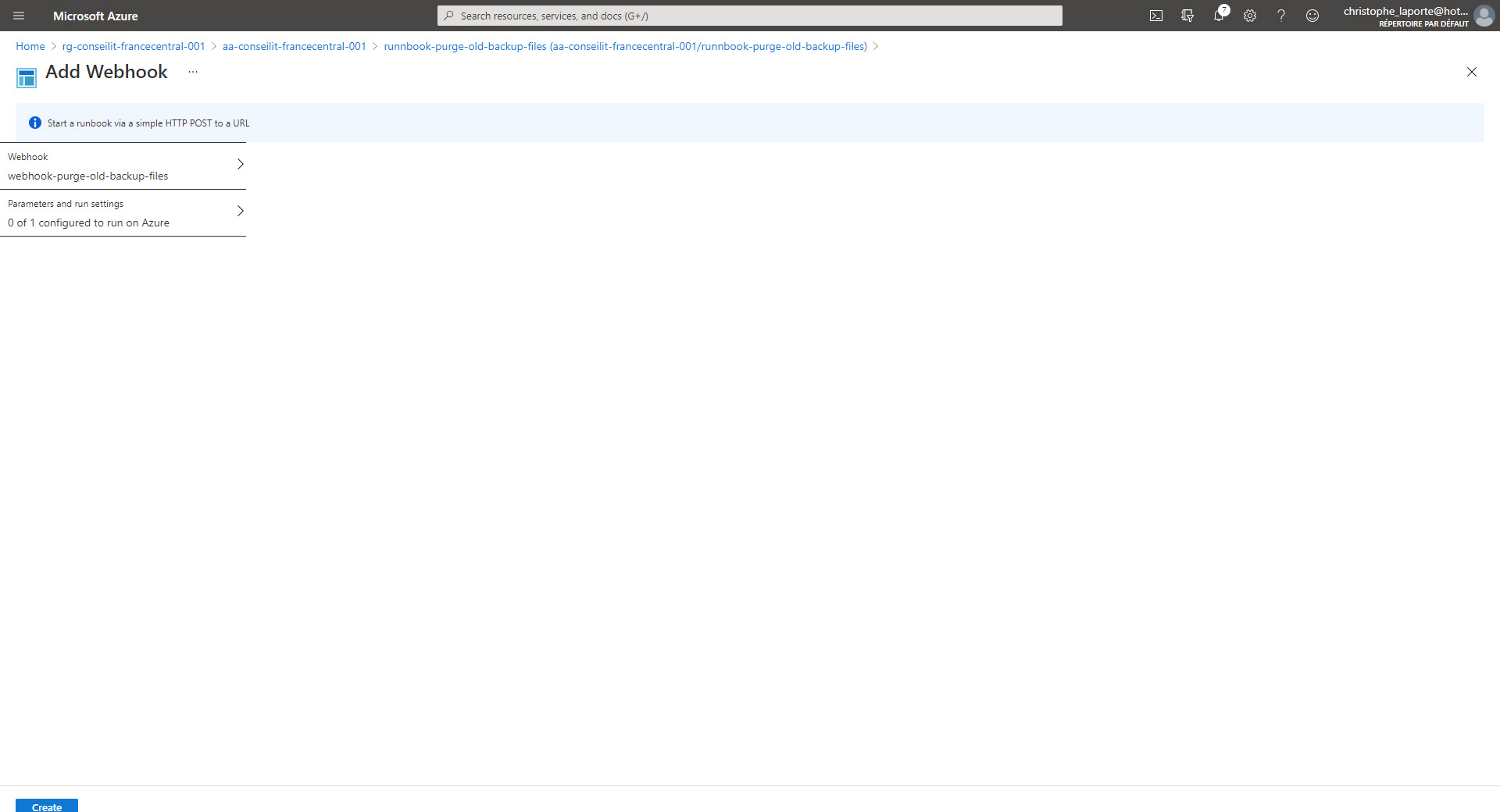
Okay, nous sommes proches de la fin … Il faut à présent créer un Topic système et créer un abonnement

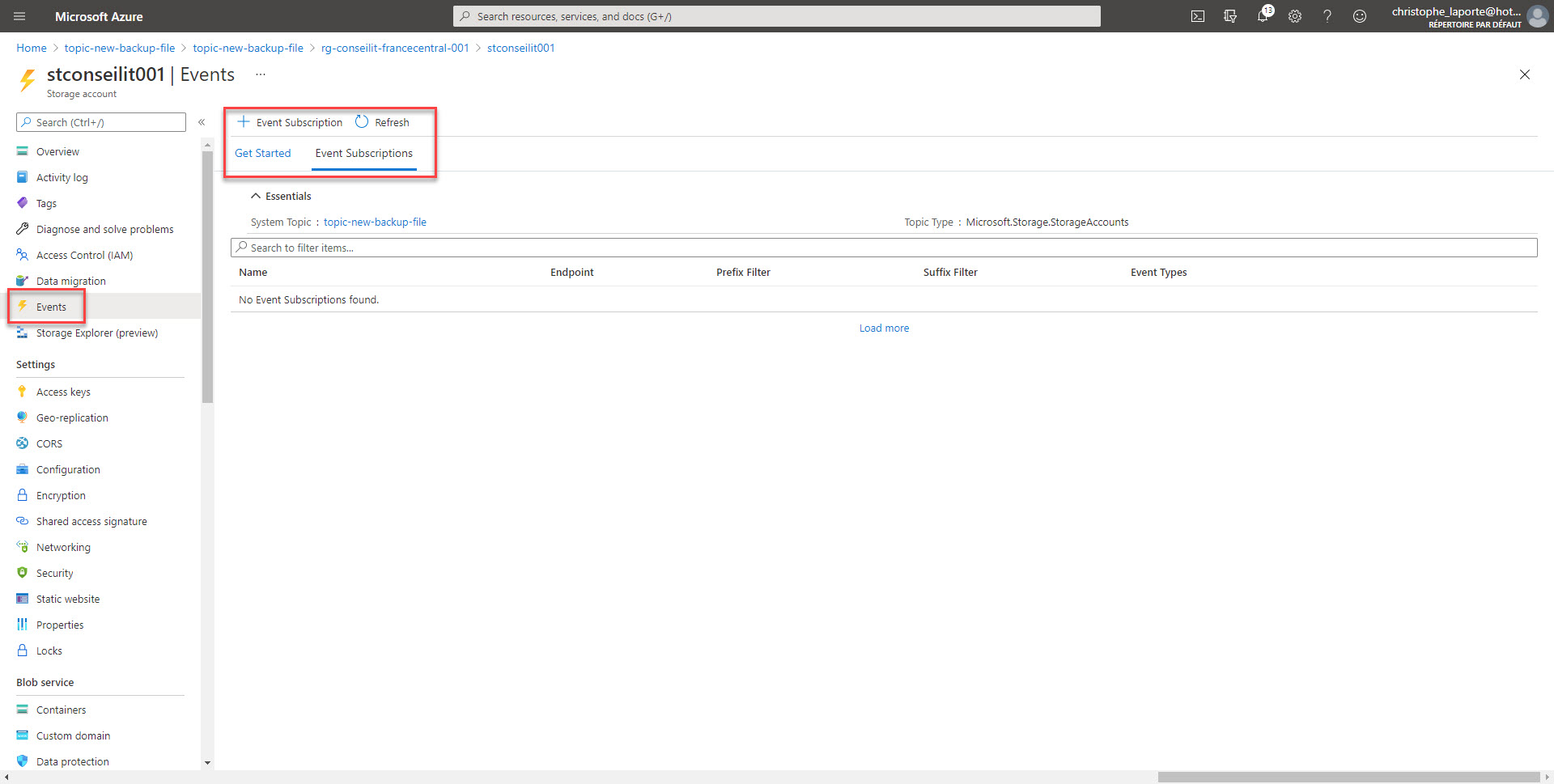
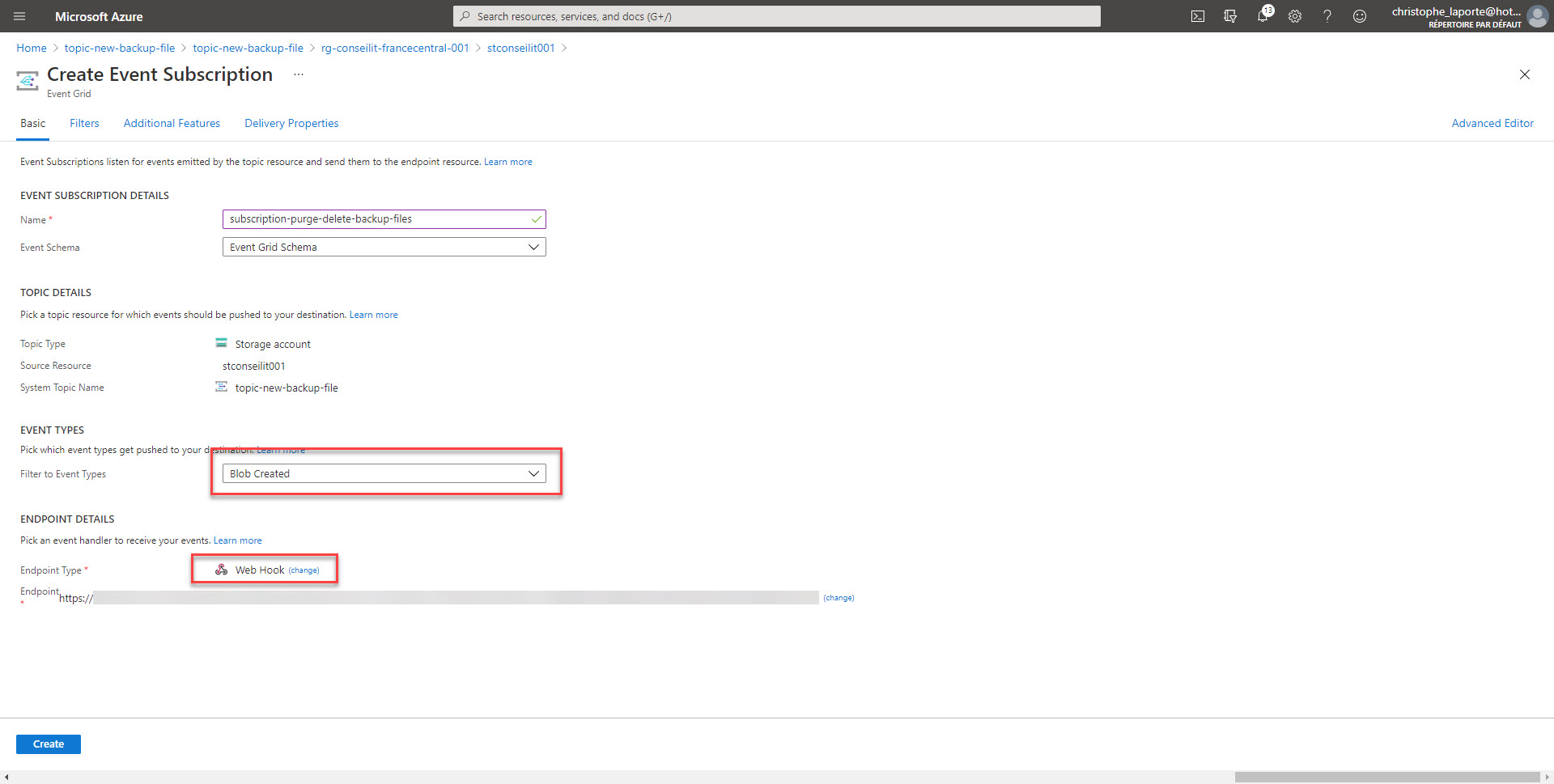
Pensez à filtrer les évènements pour ne conserver que les « Blobs Created » et configurez le WebHook avec l’URL préciseument mise de côté lors d’une précédente étape.
Comme dit précédement, l’idée n’est pas d’activer le runbook lors de la création d’audit, ou bien de xEvents, c’est pour cela que nous allons filtrer en fonction du sujet avec le conteneur sql-backup.
Et afin de ne pas déclancher d’évènement multiples lors de la création d’un backup, nous allons mettre un filtre avancé avec « data.api » contains « PutBlockList ». En fait cette API est appelée en fin de sauvegarde une fois tous les Blocks ( API « PutBlock ») écrits. N’hésitez pa sà faire appel à votre moteur de recherche favori pour de plus amples détails sur le mode de fonctionnement.

Il ne reste à présent plus qu’à tester la solution …
Côté SQL Server, nous créons le credential et démarrons une sauvegarde complète des bases système.
CREATE CREDENTIAL [https://stconseilit001.blob.core.windows.net/sql-backup]
WITH IDENTITY='Shared Access Signature',
SECRET='sp=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
GO
EXECUTE [_DBA].[dbo].[DatabaseBackup]
@Databases = 'SYSTEM_DATABASES',
@URL = 'https://stconseilit001.blob.core.windows.net/sql-backup',
@BlockSize=65536,
@MaxTransferSize=4194304,
@Compress='Y',
@BackupType = 'FULL',
@CheckSum = 'Y',
@LogToTable = 'Y'
Après quelques secondes, nous pouvons constater que des répertoires sont apparus dans le container, avec un sous répertoire « FULL » contenant la sauvegarde de chacune des bases.

Si l’on bascule sur le RunBook, nous constatons que des exécutions ont été faites, correspondant à chaque fichier de backup déposé.

Il est possible de sélectionner une exécution et de visualiser la zone Output, qui contient les données issues des lignes write-output du code PowerShell.
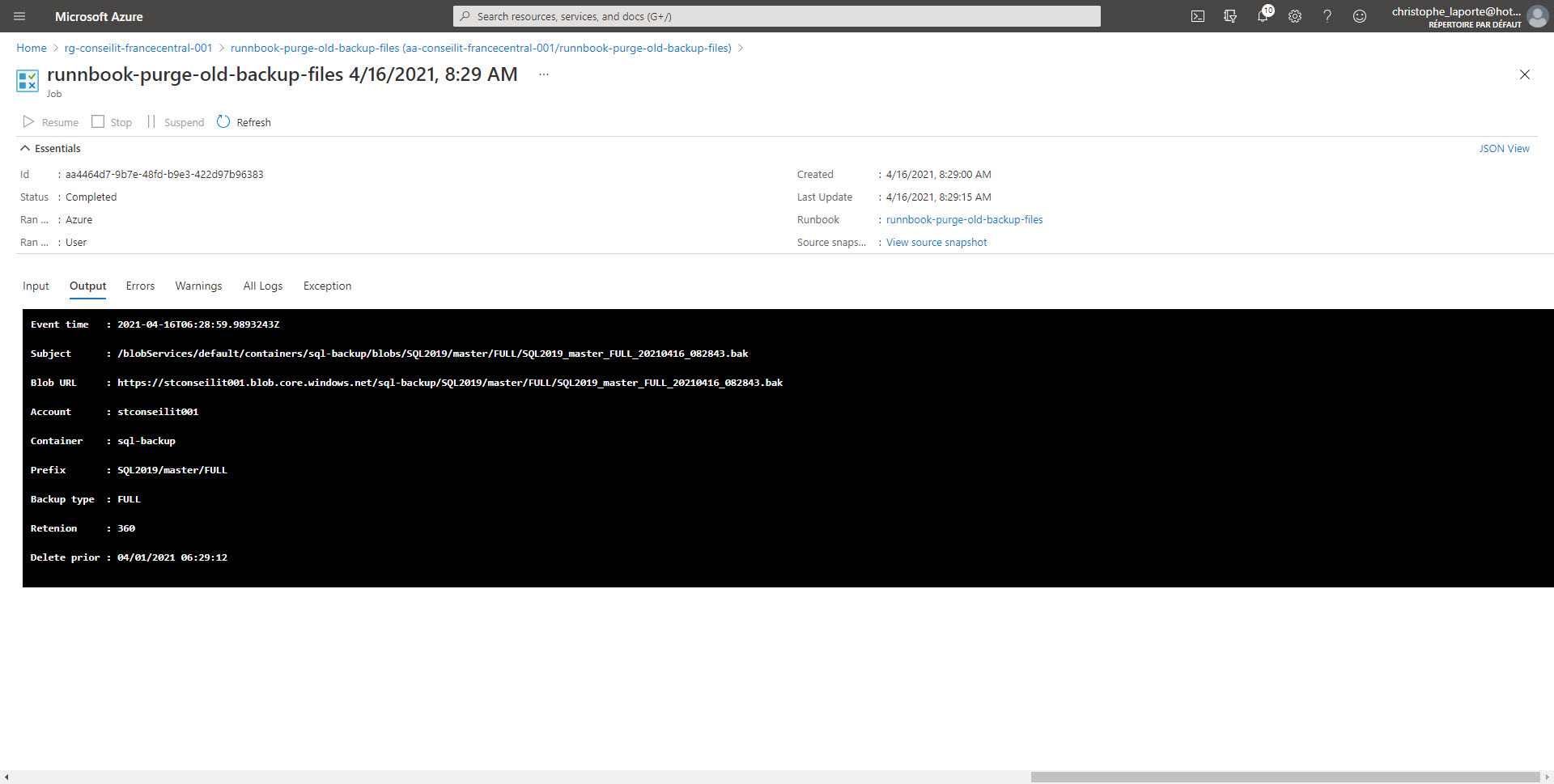
Lorsque vous aurez dépassé la durée de rétention configurée dans vos variables, la liste des fichiers devant être supprimée s’affichera alors.
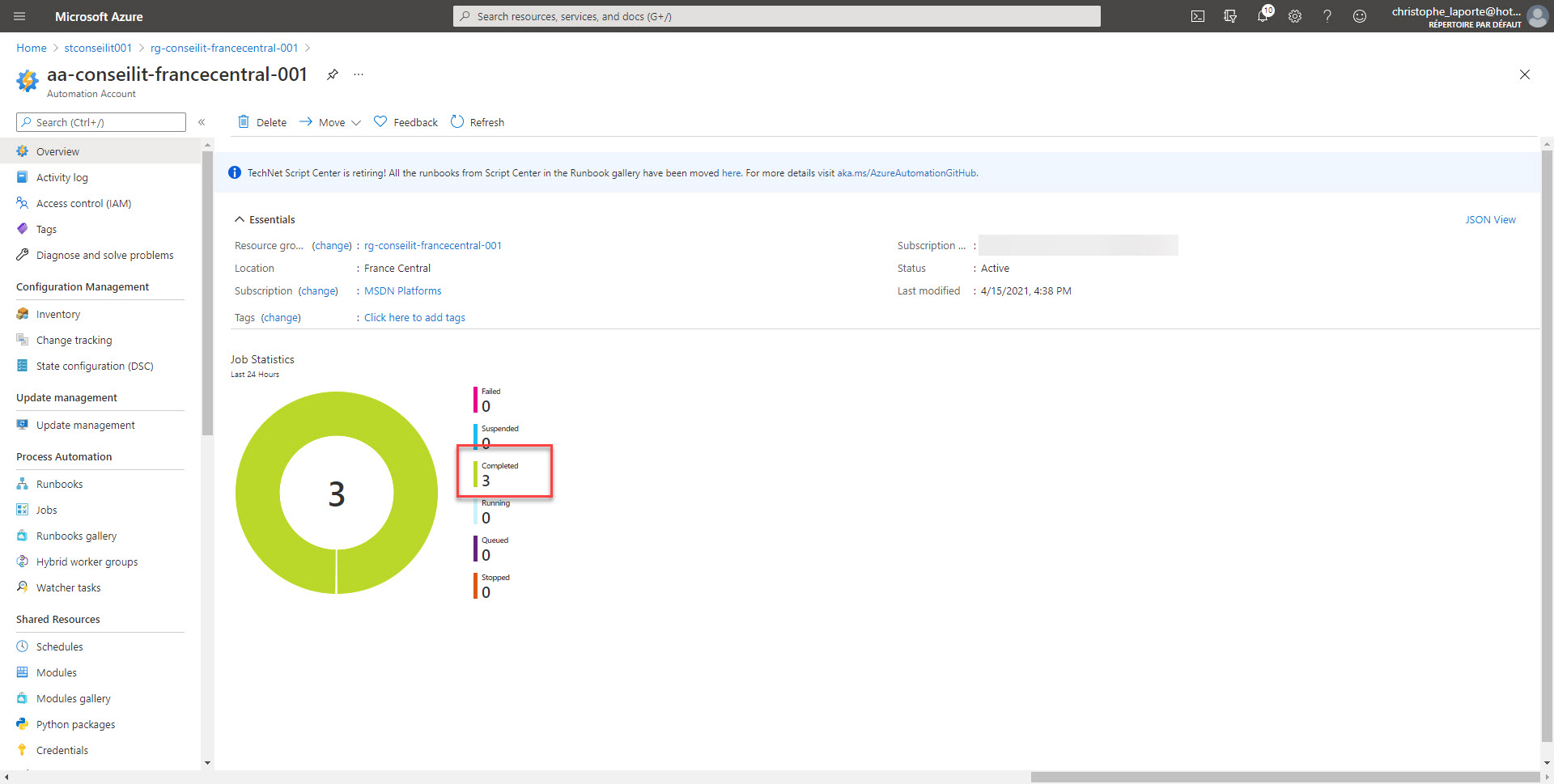
Des statistiques d’exécution sont disponibles à la fois au niveau de l’event subscriptions sur le compte de stockage, tout comme sur le compte d’automatisation.

Cette solution m’a paru être relativemetn simple à mettre en place, tout en offrant des garanties sur la rétention des fichiers, même en cas de problème au niveau des backups (pas de backup -> pas de déclanchement de la purge pour ce type de sauveagrde et pour cette base).
En fonction des cas, un simple Life Cycle Management pourrait suffire, par exemple au-delà de 30 jours déplacement des fichiers vers du stockage froid, puis au-delà de 180 jours suppression sur le stockage froid …. A vous de voir en fonction de votre politique de rétention et de votre PRA.
Happy Backups on Azure !



