Noyé dans un flux de news, j’ai failli passer à côté de celle-ci : un nouveau tier de stockage sur Azure Storage.
En effet, le tier Cold vient de s’ajouter aux déjà connus Hot, Cool et Archive. Je ne tiens pas compte ici du Premium.
Situé entre le Cool et l’Archive, son but est de stocker à plus long terme des fichiers, des sauvegardes par exemple avec un cout largement inférieur à niveau Cool mais sans avoir à supporter le délai de réhydratation lié au tier Archive.
Si vous souhaitez bénéficier d’une réserve de capacité, le prix est encore inférieur.
Mais, logiquement, le cout d’accès est notablement supérieur au niveau Cool, d’où son utilité pour la rétention à long terme (plus de 90 jours) sans avoir à supporter une latence d’accès élevée, quelques millisecondes contre quelques heures …
L’actualité récente nous a encore montré que même un grand nom des acteurs du cloud public n’est pas à l’abri d’un évènement mettant en péril les services hébergés.
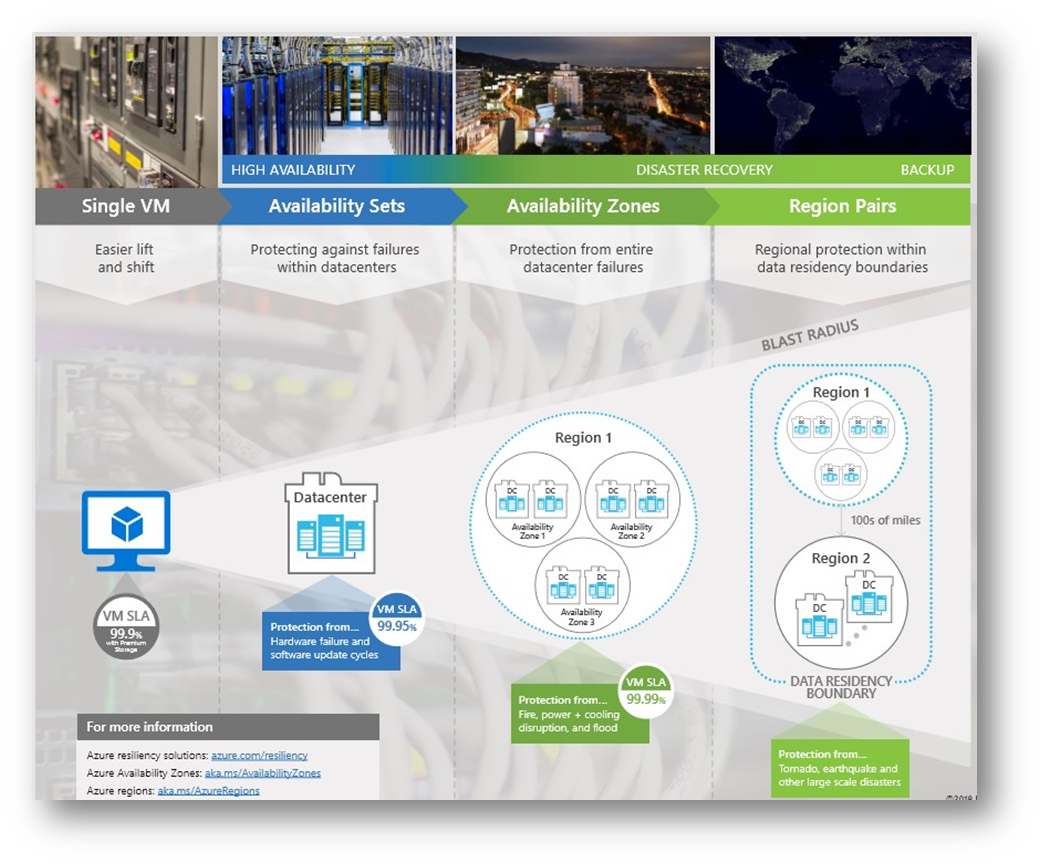
Rappelons au passage qu’une région Azure est segmentée en plusieurs zones, chacune étant composée d’un ou plusieurs Datacenter(s) équipés d’une alimentation électrique, d’un système de climatisation et d’une infrastructure réseau indépendants.
En France, nous disposons principalement de la Zone France Centre, avec 3 availability zones, et France Sud en zone pairée.
Faire confiance à un hébergeur ne nous dédouane pas de concevoir une architecture résiliente pour faire face à une perte de zone ou, plus grave, à une perte de région.
Mon activité est principalement centrée sur les données, et donc assurer leur disponibilité est vital. Outre la redondance géographique des sauvegardes (stratégies 3-2-1, 3-2-1-1-0, 4-3-2) pour assurer un PRA, le PCA doit également offrir cette possibilité, en lien avec la criticité de l’application il va de soi.
Et c’est ce dernier point qu’il est plus difficile de satisfaire pour bien des sociétés ne disposant pas de datacenters géographiquement répartis. Nos Public Cloud Providers offrent ces services, de manière simple, alors pourquoi ne pas en profiter ?
D’un point de vue stockage de fichiers, se priver de redondance de zone, ou de redondance géographique ne fait pas sens, si ce n’est économiser quelques euros, ce que vous regretterez à la moindre défaillance. Voici par exemple la répartition d’un compte de stockage ZRS, sachant qu’il est également possible d’opter pour du GRS voire du GZRS.
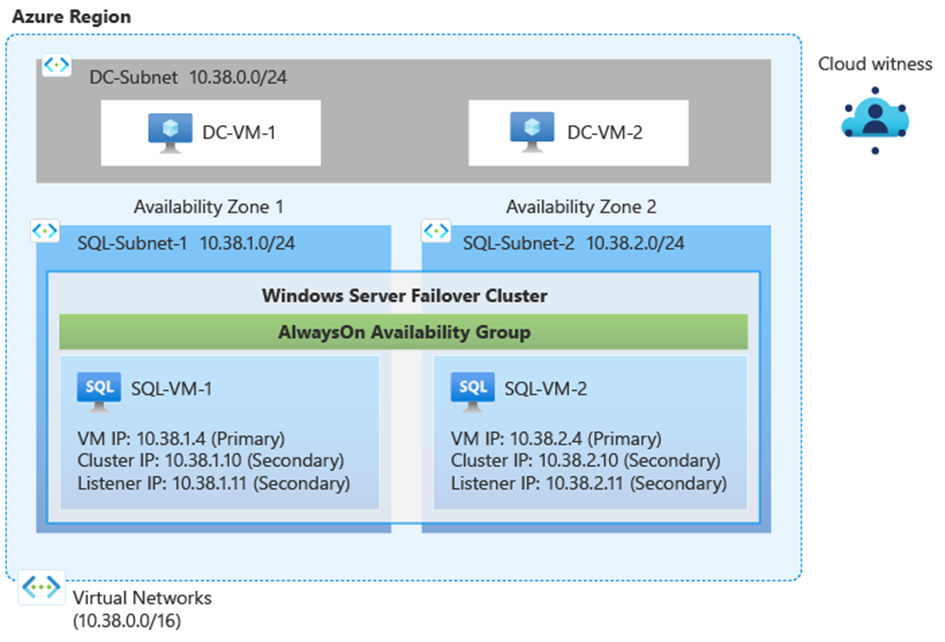
D’un point de vue bases de données, disons SQL Server au hasard, quel que soit le type de service il est possible d’opter pour une résilience de zone.
En mode IaaS, l’utilisation de VMs dans des Availability Zones :
En mode PaaS, pour Azure SQL Database & SQLMI, une option permet d’utiliser du stockage zone redondant en mode General Purpose.
Bien évident, en mode Business Critical cette option est également possible sous une forme différente.
Cela ne tient pas compte de la possibilité de travailler en sus avec la géo-réplication et des auto-failover groups.
Alors, plus de raison de perdre l’accès à vos données, et par extension, une conception robuste de vos applications devrait les rendre résilientes à la perte d’une zone, voire d’une région.
Besoin de conseils ou de formation ? Vous savez où me trouver …
Je donne très rarement dans le sensationnel mais j’avoue que les titres des quelques agrégateurs de News que je regarde me laissent pantois ce matin. On voit des articles relatant des certains d’instances SQL Server infectées par une porte dérobée, nommée Maggie. Ou bien que le malware Maggie s’attaque aux serveurs SQL de Microsoft.
Bon, il est temps de remettre les choses dans leur contexte.
Une équipe de chercheurs a bel et bien découvert quelque chose, de réel, soyons clair, et ne minimisons surtout pas l’impact que cela peut avoir sur votre système d’information. Donc oui, ce n’est pas à prendre à la légère.
Mais j’aurais tendance à dire que l’on est quand même dans la lignée des articles putaclic.
Remettons les choses dans leur contexte …
Ce malware ne s’immisce pas dans SQL server. C’est quelqu’un qui l’a volontairement ajouté ! Depuis que je travaille sur SQL Server, ¼ de siècle pour faire simple, SQL Server a toujours proposé une option pour ajouter du code « Externe », sous forme de DLL. Donc un gentil développeur créé du code, vous donne une DLL signée, et vous en tant que DBA vous allez l’ajouter dans SQL Server. Ensuite, ce code pourra tout simplement être appelé au travers de procédure stockées étendues.
Et depuis 25 ans, j’alerte sur les problèmes que cela peut engendrer niveau sécurité et déconseille fortement ce genre de choses. Soyons claire encore une fois. Il y a bien un risque, mais c’est quand même vous qui l’avez ajouté. Et puis un nom de DLL aussi bien choisi, « sqlmaggieAntiVirus_64.dll » on se dit, ben oui, je vais l’ajouter, y’a pas de risque …
Bon, vous allez me dire mais ce n’est pas nous qui l’avons ajouté. Ah, oui, je ne peux pas tout le temps prouver qu’effectivement ce n’est pas vous. Mais si je ne peux pas le prouver c’est encore votre faute car vous utilisez toujours SA pour effectuer vos tâches d’administration !!! Alors qu’un groupe de sécurité Windows, avec un login spécifique par administrateur, ce n’est pas très compliqué … Oui, mais quand on est sysadmin, on prend l’identité de l’utilisateur dbo dans les bases de données. Hey, les nouveautés de SQL Server datant d’une dizaine d’années, ça vous parle ? Utilisez la permission Control Server en lieu et place du rôle sysadmin et vous ne perdrez pas votre identité.
Heuu, et encore, une dernière chose, si ce n’est pas vous qui l’avez ajouté, dans ce cas, vous étiez déjà attaqué … puisqu’un Hacker était sysadmin de votre instance …. Premier réflexe de ces derniers : utiliser vos serveurs liés ! En effet, dès que l’on possède le droit de se connecter à SQL Server, on dispose de la permission d’utiliser les serveurs liés, que vous avez peut-être configurer pour utiliser le compte SA sur le serveur distant. Ben ouaip, c’est tellement lourd à gérer la sécurité SQL Server. Pas envie de s’embêter, donc allez, on y va avec SA !
Et puis, ajouter un fichier … Il faut aussi avoir accès au niveau OS … On peut aussi tourner le regarde vers les autorisations données pour faire du RDP, pour les accès disque et réseau … Sans compter avec le compte de service de SQL Server qui doit respecter les principes de moindre privilège …. Et que dire des Firewall qui sont désactivés sur les OS ….
Et donc c’est SQL server qui a une faille de sécurité et qui subit une attaque d’un malware. Désolé, mais le problème est clairement entre la chaise et le clavier. Alors, oui il est probable qu’il existe des failles de sécurité dans SQL Server, comme dans tout logiciel, mais clairement, les statistiques montrent que sur les 10 dernières années, voire plus, très très peu de failles ont été découvertes sur SQL Server, contrairement à certains concurrents … Je dis ça, je ne dis rien !
Bon, je crois que ce petit coup de gueule est terminé.
En conclusion : si vous ne savez pas gérer vos SQL, laisser faire ceux qui savent. La sécurité fait aussi partie des tâches qui incombent au DBA.
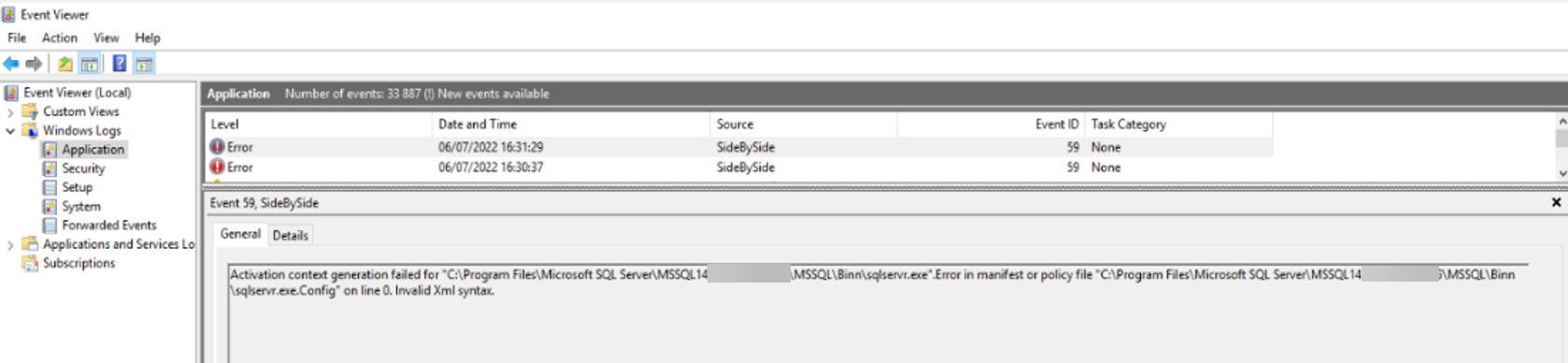
Un bref article afin de relater un cas de figure rencontré récemment chez un client. Pour des raisons que je ne vais pas développer ici, quelques instances SQL ne voulaient plus démarrer. Tout comme l’agent SQL associé, ainsi que le service Intégration Services.
Le message d’erreur stipule une syntaxe incorrecte dans le fichier XML de configuration.
Lorsque l’on tente d’ouvrir ce fichier via un éditeur de texte, effectivement, ce fichier affiche des symboles plus ou moins compréhensibles, mais en rien un format XML, en effet.
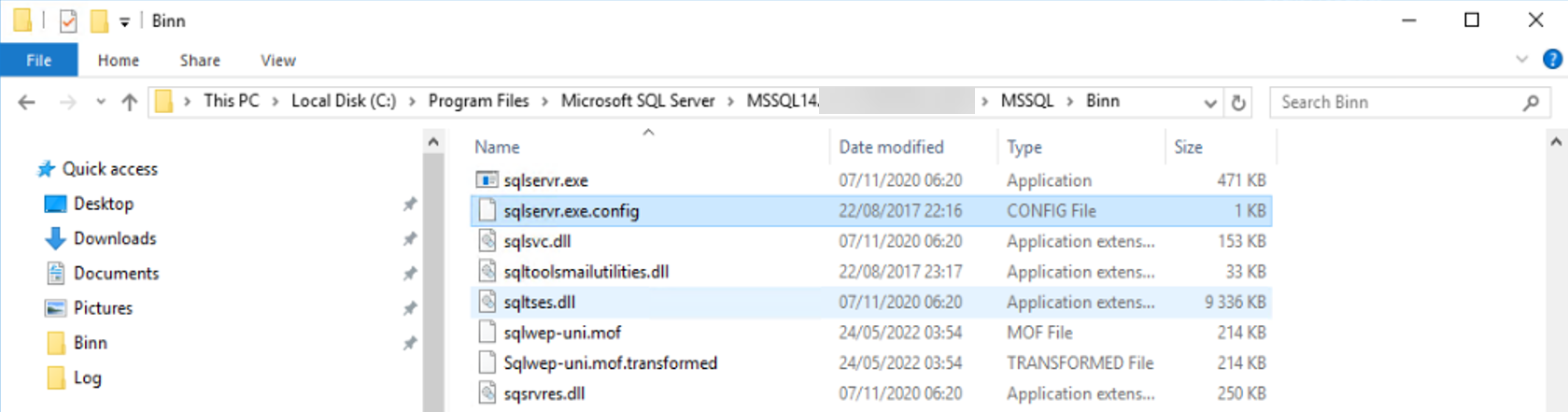
La résolution est relativement simple, recherchez une instance SQL saine, avec un numéro de version identique, et recopiez ces fichiers XML dans le répertoire Binn de l’instance en erreur.
Ce week-end avait lieu le SQL Saturday Haiti, seconde édition. J’ai eu le plaisir de participer à l’évènement avec une session sur la mise en pratique des groupes de disponibilité vi ades scripts PowerShell & dbaTools.
Vous pouvez retrouver la vidéo sur la chaine du Haitian data Driven Community.
Les slides ainsi que le code source des démos est présent sur mon espace OneDrive public ainsi que sur mon github.
L’utilisation de PowerShell est devenue un standard de l’administration, y compris pour les DBAs. Bien qu’il existe des cmdlets spécifiques à SQL Server, la bibliothèque dbaTools est devenue un standard de fait.
Plusieurs centaines de modules sont disponibles, simples à installer et utiliser. Ce projet communautaire permet d’automatiser des tâches comme l’installation et la configuration de SQL Server, l’application de cumulative update ou de service packs, la migration de base vers une nouvelle instance, et donc toutes les copies d’objets comme les Logins, les Jobs, etc …
La mise en œuvre des groupes de disponibilité, bien que simple en T-SQL mérite aussi que l’on automatise le processus en PowerShell & dbaTools.
Cette courte vidéo présente la mise en oeuvre d’un cluster Windows et l’implémentation des groupes de disponibilité (AlwaysOn Availability Groups) au travers des modules DBATools.
Les différentes étapes de la mise en oeuvre d’un groupe de disponibilité sont les suivantes : – Activation de la fonctionnalité WSFC sur les noeuds – Test du cluster – Formation du cluster – Ajustement des paramètres du cluster – Configuration du Quorum – Autorisation du CNO à créer des enfants dans le conteneur ou OU Active Directory – Activation de la fonctionnalité HADRON sur le service SQL Server – Création des points de terminaison – Création des logins des services SQL sur les réplicas – Création du groupe de disponibilité – Création du listener – Création d’une routing list – Ajout d’une base dans le groupe de disponibilité
Microsoft Azure se compose de plus de 200 services à l’heure où ce billet est rédigé. Certains sont très connus et largement utilisés, comme les services Web, des machines virtuelles ou les services liés aux données comme SQL Azure Databases dans ses différentes déclinaisons (Single Database, Elastic Pool, Managed Instance et les containers ACI ou AKS, sans oublier SQL Edge) ou les comptes de stockage. Les services d’intelligence artificielle, d’IoT, ou d’identité sont également régulièrement mis en lumière.
Et puis il y a des services, pourtant essentiels, mais dont on parle moins. Les service réseau en font partie. C’est pourtant une pièce angulaire de toute architecture dont la maitrise est assez complexe il faut bien l’avouer. Mais tout autant que l’est la maitrise d’une infrastructure réseau OnPrem ! Chaque métier a son équivalent cloud avec de nouvelles compétences à acquérir et de nouveaux défis à relever. Le passage au cloud marque le début d’un nouveau chapitre de votre vie professionnelle.
Et puis un service dont on parle finalement peu, le monitoring et l’alerting. OnPrem, il faut l’avouer c’est souvent le parent pauvre. Ce n’est pas très fun à mettre en œuvre, on se pose énormément de question sur l’outil à utiliser (Outil payant, solution OpenSource …).
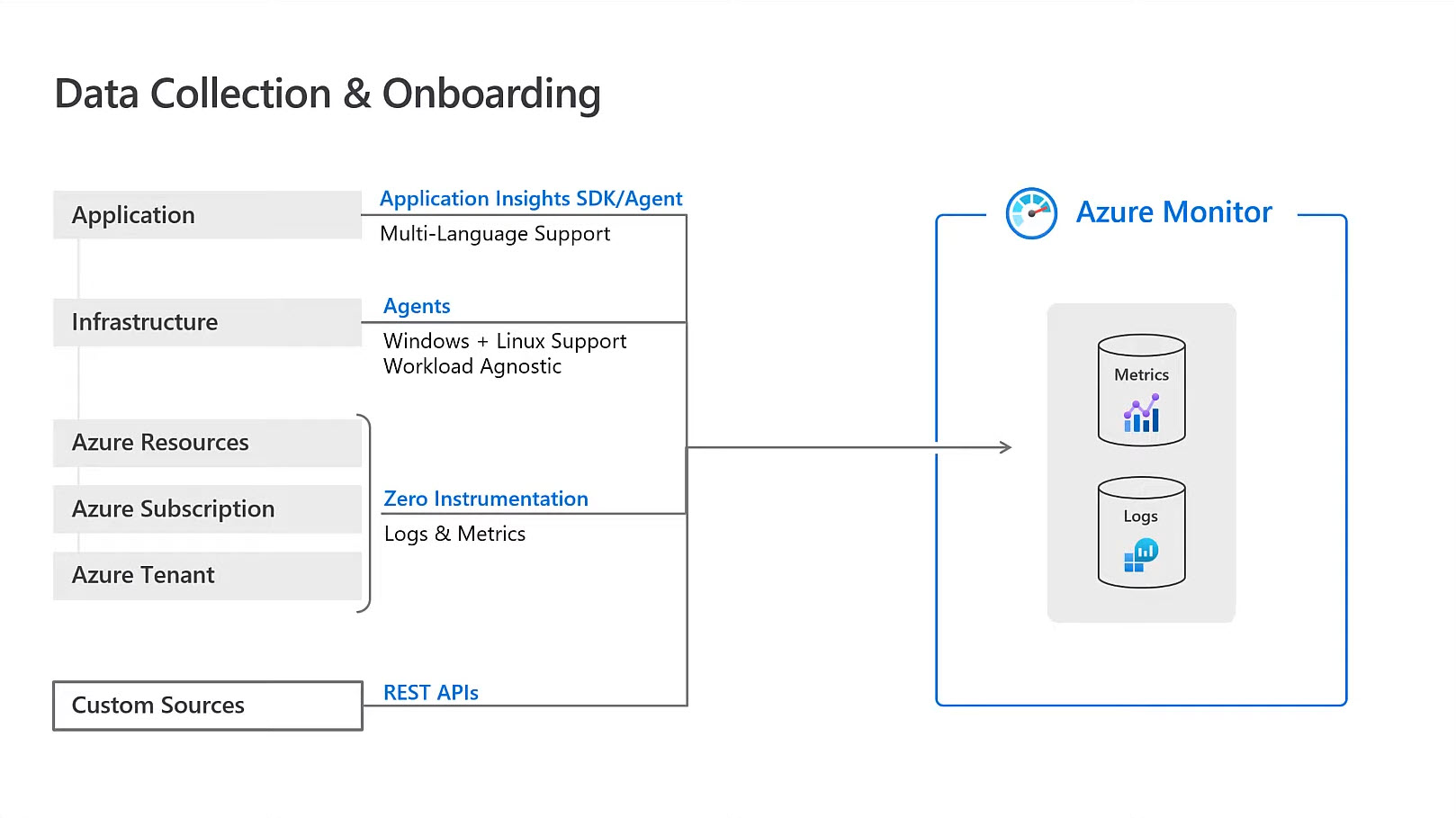
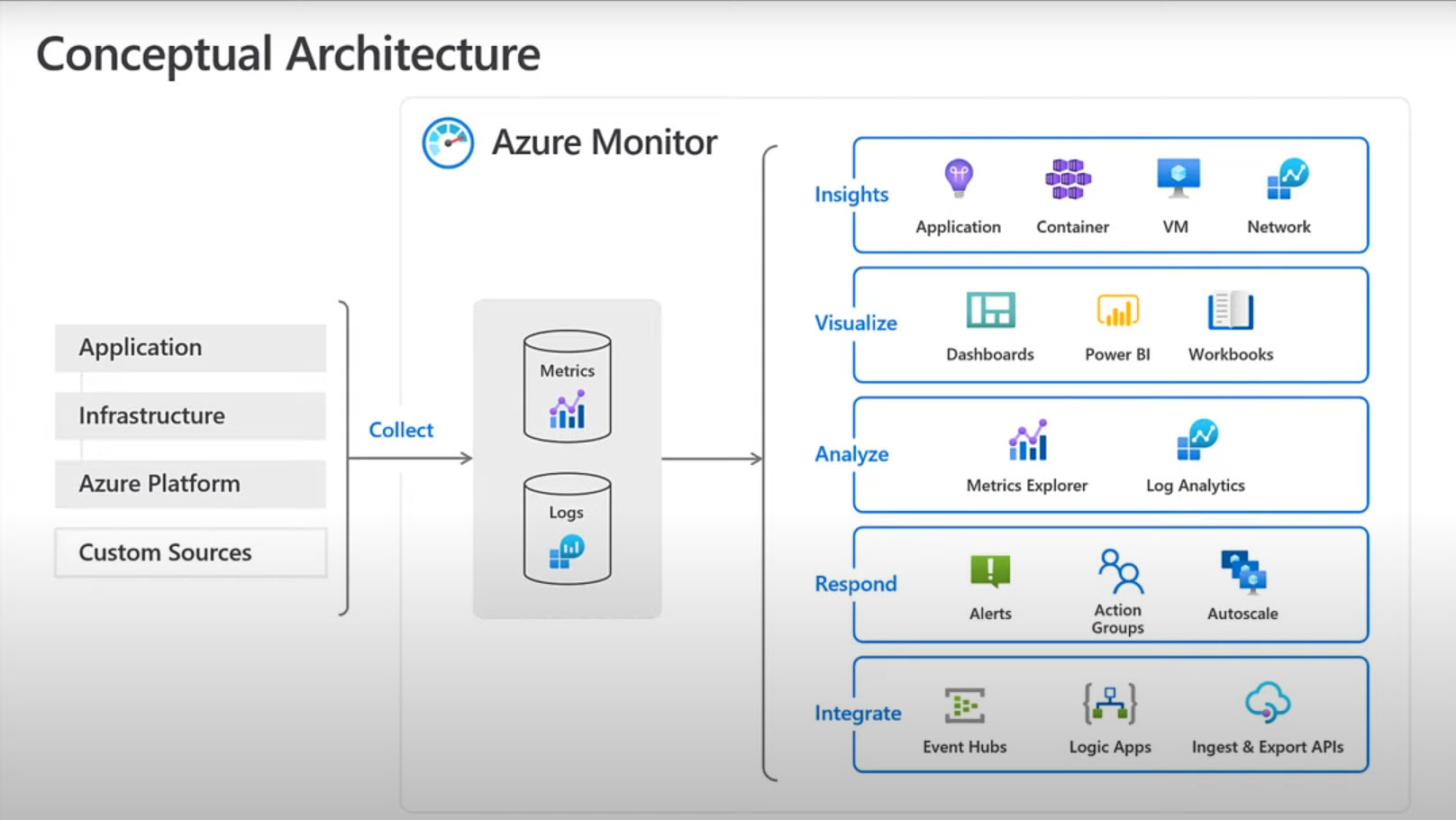
Azure Monitor offre un service très intéressant en centralisant les informations issues des métriques applicatives (votre appli .net), de l’infrastructure au travers d’agents et des différentes ressources Azures comme SQL Server par exemple.
De quoi suivre les performances de bout en bout … Un must have en termes de troubleshooting avec des outils de visualisation intégrés ou tiers (Power BI),
3 vidéos ont été publiées sur la chaine YouTube Microsoft Azure. Prenez quelques minutes pour les consulter.
Pour SQL Server, au-delà des métriques « standard », je vous suggère de ne pas faire l’impasse sur SQL Insights, qui ajoute une VM Telegraf, qui va vous permettre d’unifier la vision des performances IaaS et PaaS, y compris si vous avez des cluster Always On Availability Groups.
La surveillance, l’automatisation de certaines tâches en réponse à des conditions de performance, l’observabilité sont des thèmes qui prennent de plus en plus d’importance au sein d’une DSI. Gageons qu’Azure Monitor va encore évoluer …
Depuis bien des années j’utilise des NAS Synology. D’une part pour stocker des fichiers liés à mon activité professionnelle, come stockage partagé de mon cluster de voyage (en plus d’utiliser le stockage cloud OneDrive et Dropbox synchronisés sur 4 appareils distincts !) mais aussi pour des besoins plus personnels comme le support des photos entre autres.
Pourquoi un NAS plutôt que des disques externes : tout simplement pour pouvoir bénéficier de la redondance RAID1 ou RAID5 offerte par ces boitiers. Oui, j’ai aussi des disques externes, en archive externalisée mais je n’ai qu’une trais faible confiance quant à la durabilité. 1 égale 0. Si vous perdez ce disque, vous avez tout perdu. 2 égale 1. Avec un RAID1, si un disque tombe en panne, vous avez la chance de récupérer vos précieuses données car elles sont également présentes sur le second disque.
Et pour être transparent, je n’ai pas 1 NAS, mais 3, avec des synchronisations entre ces différents appareils. Pour ceux qui ne me connaissent pas, oui, je travaille énormément sur les volets la partie HA et DR de SQL Server …
Revenons à nous moutons, ou à nos NAS. Pourquoi Synology ? Probablement parce qu’à mes yeux il s’agit du meilleur matériel, avec de surcroit une offre logicielle vraiment intéressante. Mais des constructeurs comme QNAP et autres ne sont pas loin, je ne veux pas déclencher une querelle de clochers.
Autre la gestion de mes fichiers, les NAS me servent de poste de pilotage pour la vidéo surveillance, mais également, certains modèles offrent la possibilité de prendre en charge vos sauvegardes, d’héberger des machines virtuelles ou de supporter l’exécution de conteneurs. L’article traitant des conteneurs, inutile de faire ici une liste exhaustive.
Car oui, j’ai des conteneurs qui tournent sur des VMs sur Hyper-V, mais également quelques conteneurs sur Raspberry Pi et encore d’autres sur le DSM Synology.
Sur ce Blog, plusieurs articles traitent de SQL Server dans un conteneur. Aucune raison donc de ne pas utiliser également le NAS, et cela fonctionne parfaitement.
Je vous laisse ajouter le module Docker à votre DSM.
Ensuite, si ce n’est déjà fait, c’est d’activer, au moins temporairement, l’accès SSH car il n’est pas possible d’ajouter la registry Microsoft à la configuration de Docker sur le NAS.
Tout comme on téléchargerait l’image sur un système Docker plus « traditionnel », on va se positionner en root et faire un Docker Pull.
Petite vérification dans les images, mais en version graphique cette fois-ci :
Il ne reste plus qu’à créer le conteneur en cliquant sur bouton Launch et donner les paramètre d’environnement comme on le ferait en ligne de commande.
Et ensuite valider la création du conteneur. Le conteneur est créé et en cours d’exécution.
La connexion vers l’instance SQL est à présent possible
La sauvegarde de vos bases de données est un point crucial de votre stratégie de PRA.
L’actualité récente a montré combien il était important de suivre la règle des 3-2-1 en matière de backups. 3 copies de vos données à minima dont les données de production et au moins 2 backups si possible stockés sur des média distincts (ou des baies distinctes) et au moins une sauvegarde externalisée. Car en cas de sinistre majeur sur votre datacenter principal, il est tout à fait plausible que vos sauvegardes soient également impactées. D’où l’utilité de la sauvegarde externalisée.
Autre point non négligeable à prendre en compte : les fameux cryptolockers ou ransomware qui fleurissent en ce moment. Comment se protéger contre ce risque, car un simple backup sur une baie accessible via un partage réseau laisse planer le risque… Et ce n’est pas la recopie à postériori de vos backups sur un second stockage qui vous solutionnera le problème car, potentiellement, dès le backup terminé, le handle sur le fichier est levé et donc le cryptolocker peut agir. Le fichier que vous recopierez sera alors déjà corrompu.
Compliqué donc de se sortir de cette situation a moins d’aborder la notion de stockage immuable pour vos backups. La version 11 de VEEAM de mémoire propose ce genre de choses, mais cela veut dire utiliser un outil tiers pour gérer ses sauvegardes, et j’avoue ne pas y être favorable. Avec près de 25 ans de SQL au compteur (cela remonte à 1997 pour être exact), bien des éditeurs m’ont fait les yeux doux en essayant de m’expliquer (ou en criant très fort) que c’était vraiment beaucoup mieux, mais non, désolé. Une fois votre solution en place, en tant que DBA je ne suis plus libre de mettre en place mes Log Shipping, relancer des backups pour mettre en place des groupes de disponibilité (avant l’apparition de l’auto-seeding), sans compter avec les gros Fail rencontrés sur des scénarios de restaure moins conventionnels et les schedulers fainéants qui rechignent à planifier du backup log fréquemment au risque de faire exploser des journaux de transactions… Bref très peu pour moi. Seule la partie VDI me semble viable, mais je perds beaucoup de maitrise.
Comment donc solutionner ce problème. J’avoue que la solution Azure, au travers des blobs offre l’avantage d’un accès via une URL HTTPS, avec un jeton d’accès à durée limité (je parle de block blob et pas de page blob), et un credential positionné dans SQL Server. Pas de partage réseau, donc beaucoup moins de risque !
Je ne vais pas aborder en détail ici la partie mise en place, les best practices, et les différences entre page et block blogs, ce n’est pas le propos.
Le but de cet article est d’aborder la rétention des fichiers. Comment supprimer les « vieux » backups, ceux qui ont dépassé la durée de rétention.
Les conteneurs, partie intégrante des comptes de stockage, proposent plusieurs solutions, donc certaines extrêmement simples à mettre en place.
Le plus simple consisterait à utiliser la notion de Life Cycle Management. Qui de plus naturel que de spécifier une durée de rétention et ensuite de laisser Azure supprimer automatiquement les fichiers …
Tout comme l’utilisation d’un Runbook, planifié tous les jours par exemple qui purgerait les fichiers antérieurs à notre rétention.
Mais ces deux solutions sont imparfaites à mon sens, car elles ne satisfont pas à la règle des 3-2-1. Imaginons par exemple que des sauvegardes échouent pour une raisons quelconque et que personne n’y prête attention (ne rigolez pas j’ai vu des jobs en erreur durant plus d’un an …). Votre conteneur serait alors totalement vide, puis que l’exécution de la purge n’est pas liée à l’arrivée d’un nouveau fichier.
On peut conserver le runbook pour le côté exécution de la tâche, mais pour le déclanchement, je vous propose d’utiliser la notion d’évènement : dès qu’un fichier de backup est écrit dans le conteneur, alors, une fois la sauvegarde terminée, on peut purger …
Exemple : un backup database (.bak) est déposé, on peut purger le .bak de cette base de données datant de plus de x jours. Idem pour les backups log et backup différentiels.
C’est donc ce scénario que je vous propose d’explorer dans cet article, dont les grandes étapes vont être : – Création du compte de stockage et du conteneur – Création du Runbook à base de PowerShell – Configuration d’un WebHook pour lancer l’exécution du runbook. – Création d’un Eventgrid topic – Abonnement à l’évènement de création de fichier et appel au WebHook
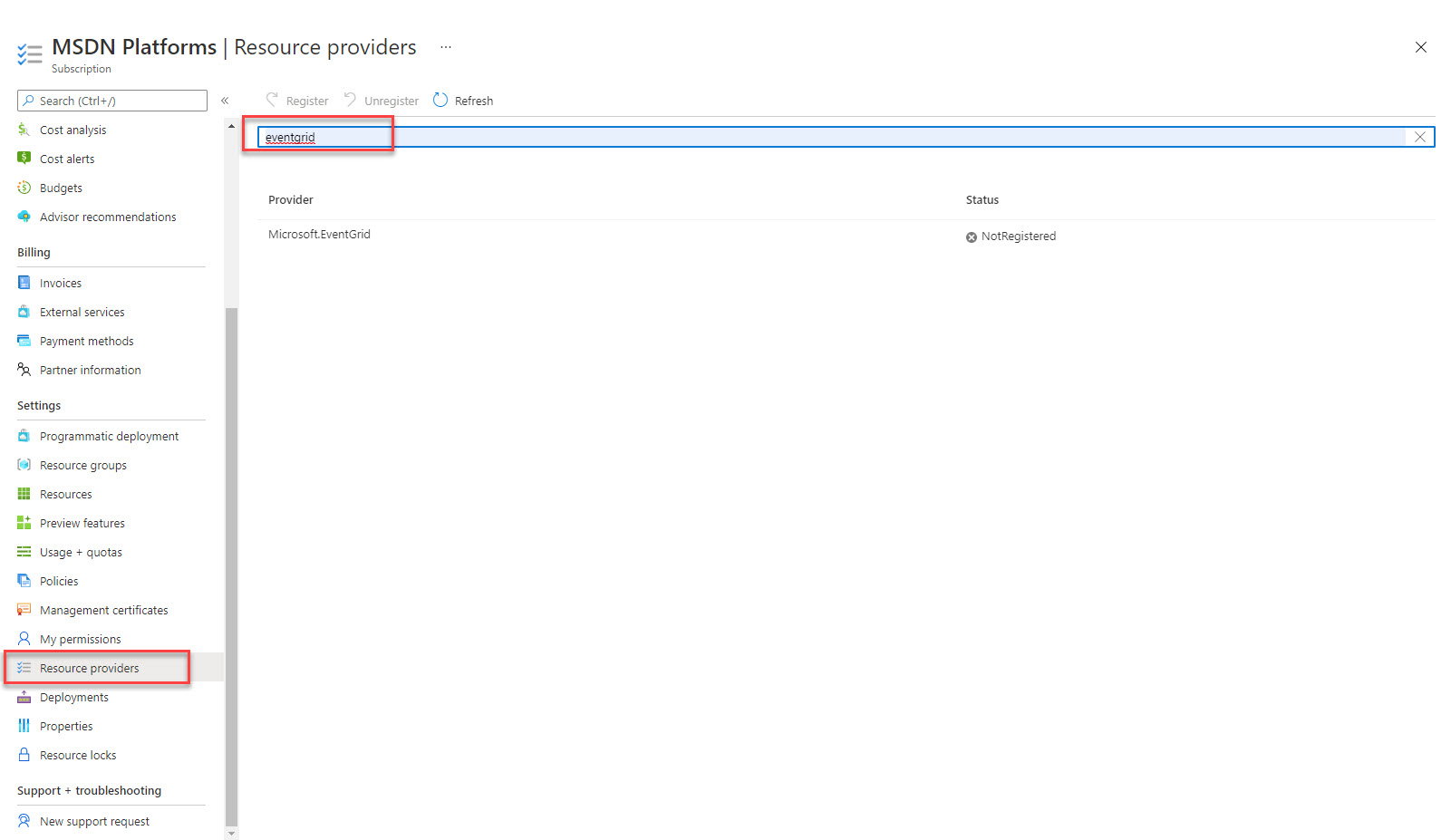
Il existe un tout petit préalable pour faire fonctionner la solution : enregistrer EventGrid dans votre abonnement. Cette ressource est à la base de « tout » Azure, mais pour pouvoir l’utiliser, vous devez l’ajouter à votre abonnement. A faire une et une seule fois …
Rendez-vous dans votre abonnement, sélectionnez l’item Resource Provider, faites la recherche EventGrid et ensuite il n’y a plus qu’à cliquer sur Register.
L’opération n’est pas instantanée, mais cela ne nous empêche pas de continuer avec la création d’un storage account.
Le propos n’est pas ici de discuter des différences entre un tiers Chaud ou un tiers Froid, vu la différence de cout au TB et à la latence induite par le tiers froid en matière de restaure, tout comme les pénalités en cas de suppression anticipée, j’ai ici opté pour un tiers chaud, en mode RA-GRS.
Si vous avez suivi le propos en introduction, utiliser une réplication LRS (locally Redundant Storage) ne fait pas sens pour du backup de données critiques pour l’entreprise. Eventuellement, opter pour une réplication ZRS (Zone Redundant Storage) pourrait s’entendre, mais vu la différence ce prix, autant opter pour une réplication GRS (Geo-Redundant Storage), qui si vous travaillez un peu avec Azure SQL Databases ou les Managed Instances, constituent l’option par défaut inclue dans le prix. Ne doutons pas un seul instant qu’il s’agisse de la solution la mieux adaptée à notre cas de figure. La redondance GZRS ne nous apporte rien, mais par contre l’option RA (Read-Access) parait couler de source. Optons donc pour RA-GRS …
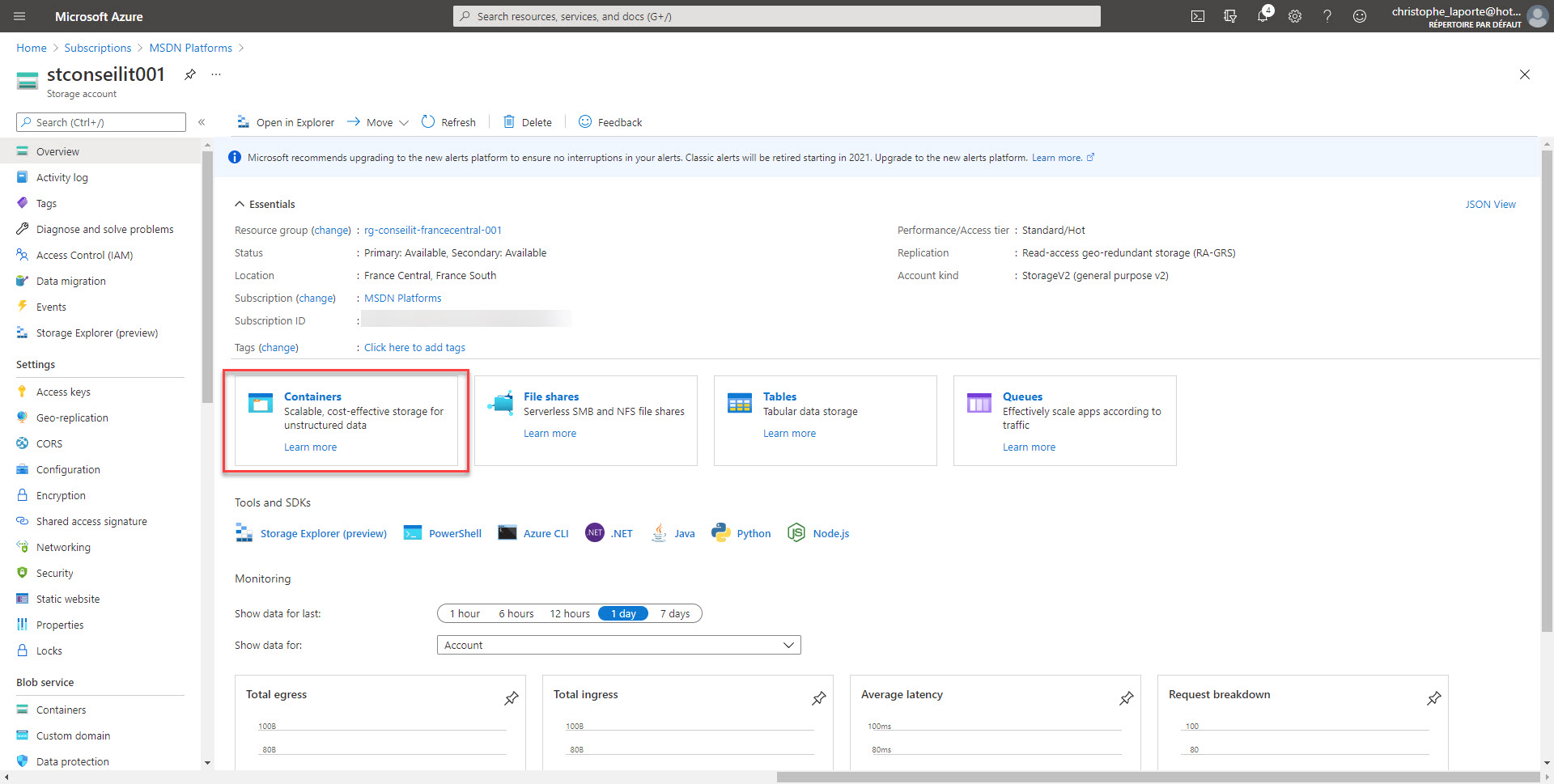
La création du compte de stockage ne pose pas de problème particulier. Ce qui me dérange le plus c’est de ne pas pouvoir appliquer ma convention de nommage comme je peux le faire sur les autres ressources Azure. 😦
Les options des différents onglets de l’assistant sont laissées telles quelles. Une fois le compte de stockage créé, cela peut prendre une minute ou deux, il suffit de créer un conteneur afin de supporter nos fichiers. Notez qu’il est possible de créer plusieurs containers, pour ma part j’ai souvent « sql-backup », « sql-backpac », « sql-audit », « sql-xevent » et « sql-bulk ». Cela couvre une grande majorité de mes besoins. Le nom que vous allez donner à cotre conteneur va recouvrir une certaine importance dans le filtrage des évènements, car il n’est pas question de purger des fichiers d’audit lorsque nous en créons un nouveau. Ou même de supprimer un fichier xEvent lorsqu’un backup est créé.
Ensuite, la création d’un RunBook nécessite la présence d’un compte d’automatisation, dont la création ne requiert pas d’attention particulière.
Vous noterez au passage que 3 Runbooks ont été créé par défaut, ce sont des exemples que vous pouvez bien entendu supprimer.
Il suffit ensuite d’aller sur le compte d’automation et de créer un RunBook
Afin de rendre le système relativement générique, j’ai opté pour 3 variables, chacune relative à la rétention de chaque type de sauvegarde : Complète, Différentielle et Journaux de transaction.
Une fois fait, nous pouvons passer à la partie création du Runbook de type Powershell.
Et d’ajouter du code afin d’effectuer les travaux de purge de fichiers.
Procédez ensuite à la sauvegarde et à la publication du code, ce qui le rendra exploitable.
Mais revenons quelques instants sur ce bout de code pour éviter un bête copier/coller sur votre environnement.
En premier lieu, nous trouvons un paramètre de type Object, sérialisé en JSON et qui va décrire l’évènement (n’oubliez pas que ce RunBook sera appelé via un EventGrid et un Topic d’ajout de nouveau fichier sur le Container).
Voilà à quoi pourrait ressembler le document JSON :
L’idée consiste alors à analyser cette URL qui caractérise totalement le travail que nous devrons réaliser dans le code PowerShell pour purger les backups de la base Instance et base. Tout d’abord, sachez que les backups sont réalisés au travers de la solution de maintenance écrite par Ola Hallengren et dont j’ai déjà eu l’occasion de présenter que ce soit dans ce blog ou au travers de mes vidéos consacrées aux dbaTools. Et cela va nous faciliter la tâche car une structure de dossiers et sous dossiers va automatiquement être créée dans le container.
L’URL contient donc les informations du Container, de l’instance SQL, de la base et du type de backup. Il ne reste alors qu’à extraire ces informations.
La notion de préfixe revêt toute son importance car il s’agit tout simplement du « répertoire » dans lequel nous devons effectuer la purge de fichier. Dans notre cas, une sauvegarde FULL sur la base Master de l’instance SQL2019.
Maintenant que nous avons accès au type de sauvegarde, nous recherchons dans les variables créées précédemment sur le compte d’automatisation quelle est la durée de rétention qui s’applique et calculons la date d’ancienneté maximale :
Enfin, nous récupérons le contexte de stockage, recherchons tous les fichiers antérieurs à la date d’ancienneté maximale dans le « répertoire » en question avant d’afficher les fichiers correspondant au critère et de les supprimer (en fonction du booléen).
Tout est donc prêt à présent pour l’exécution de la purge, il reste à se préoccuper du déclanchement des opérations.
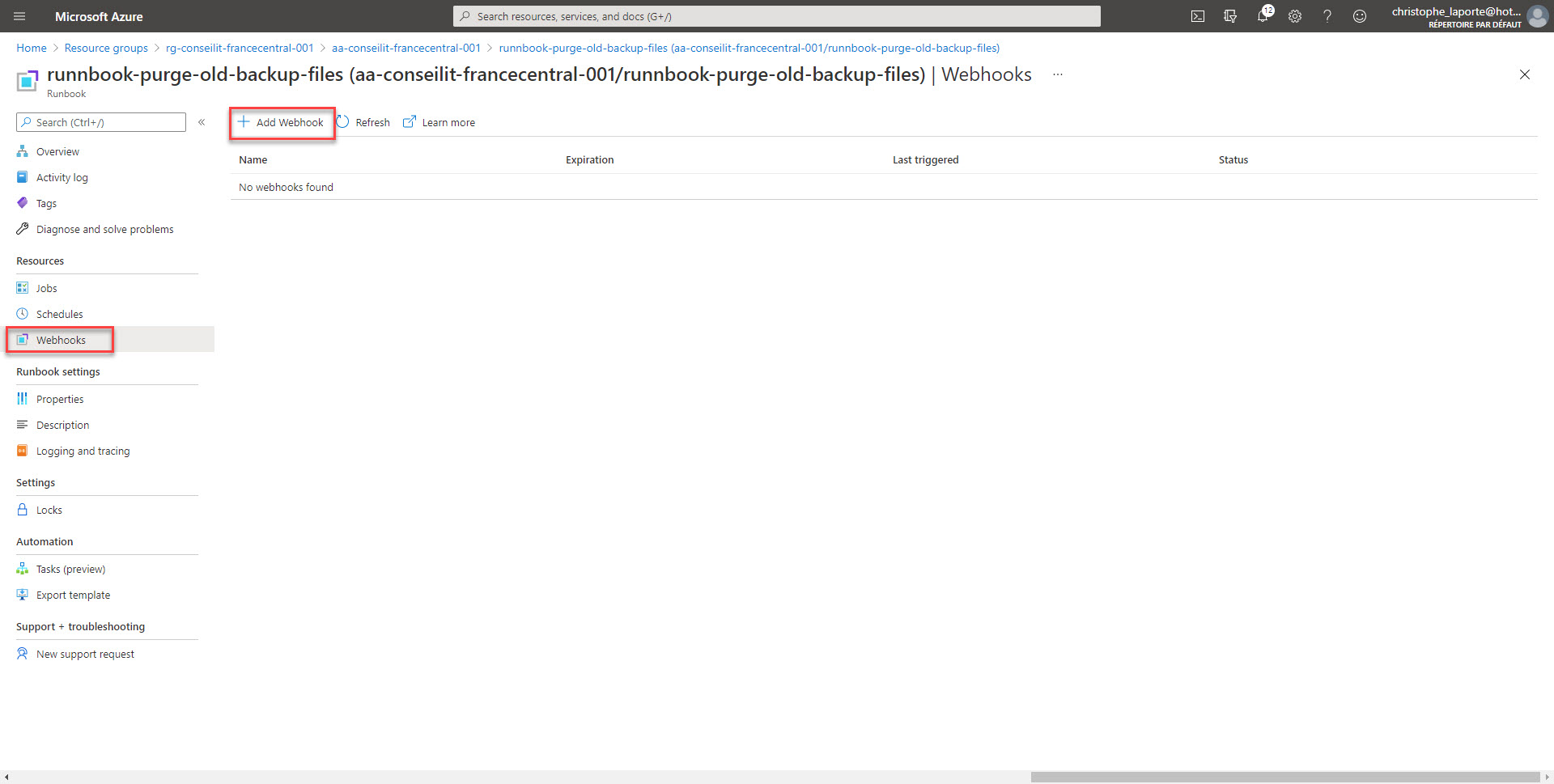
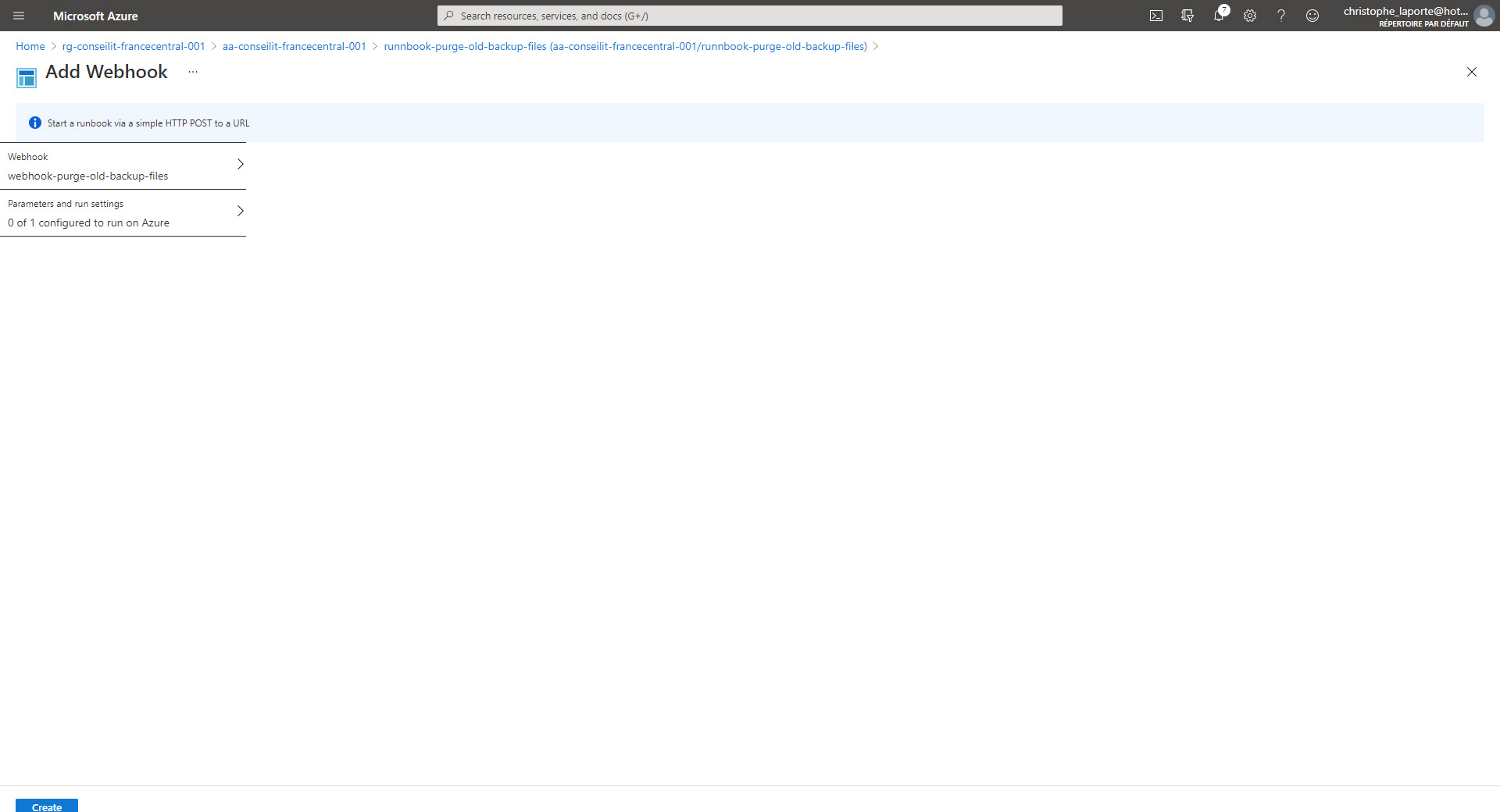
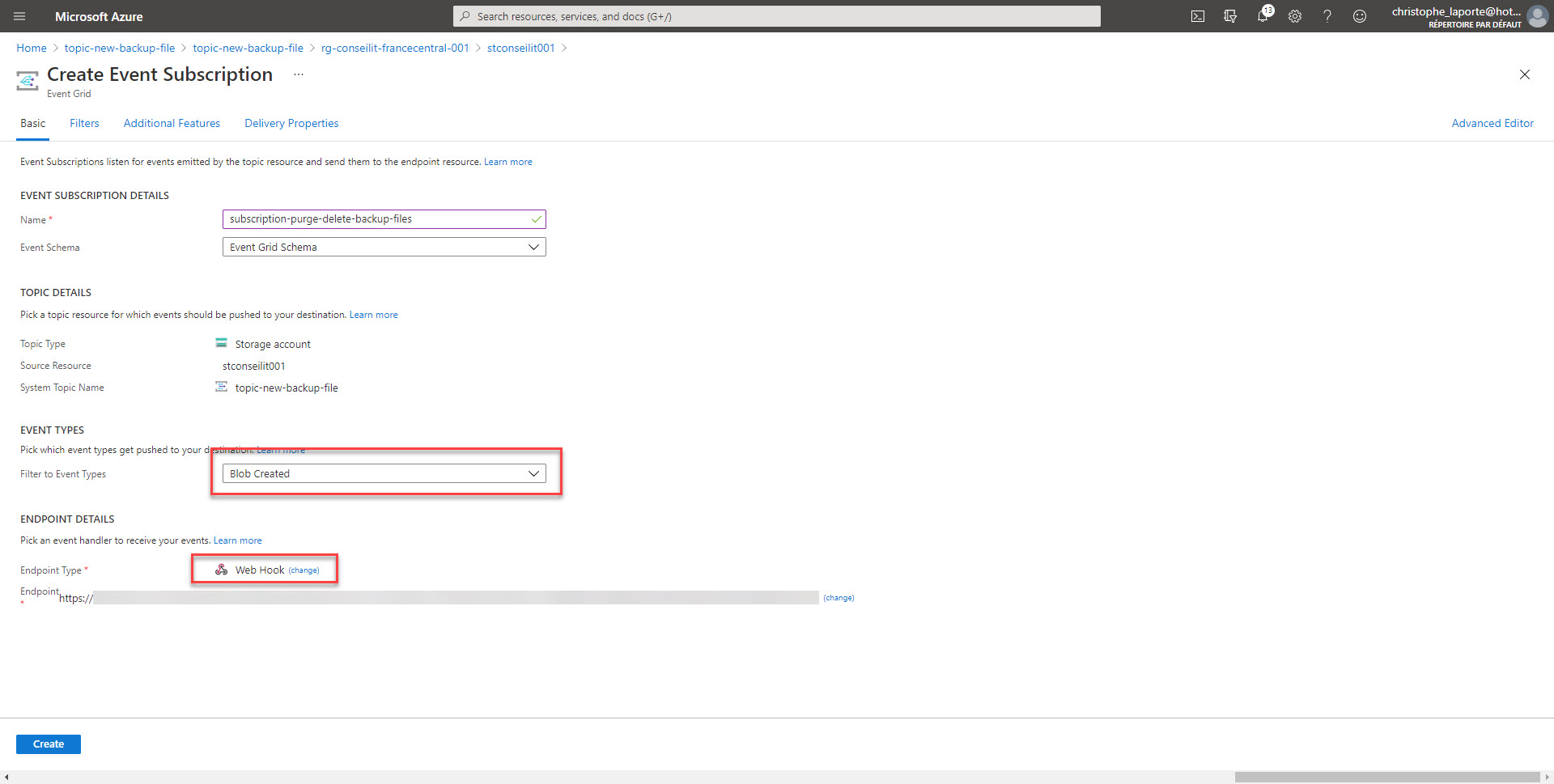
Pour ce faire nous allons créer un WebHook sur le RunBook. Pensez à copier l’URL du WebHook car pour des raisons de sécurité, pour ne pourrez plus y accéder une fois créée. Il s’agit là de sa seule protection …
Attention à la durée limite d’utilisation également !!! Allez ensuite sur l’onglet paramètres, il n’est pas nécessaire de mettre une valeur pour le paramètre WebHookData mais c’est obligatoire de valider (par le OK) cette étape dans le process de création du WebHook.
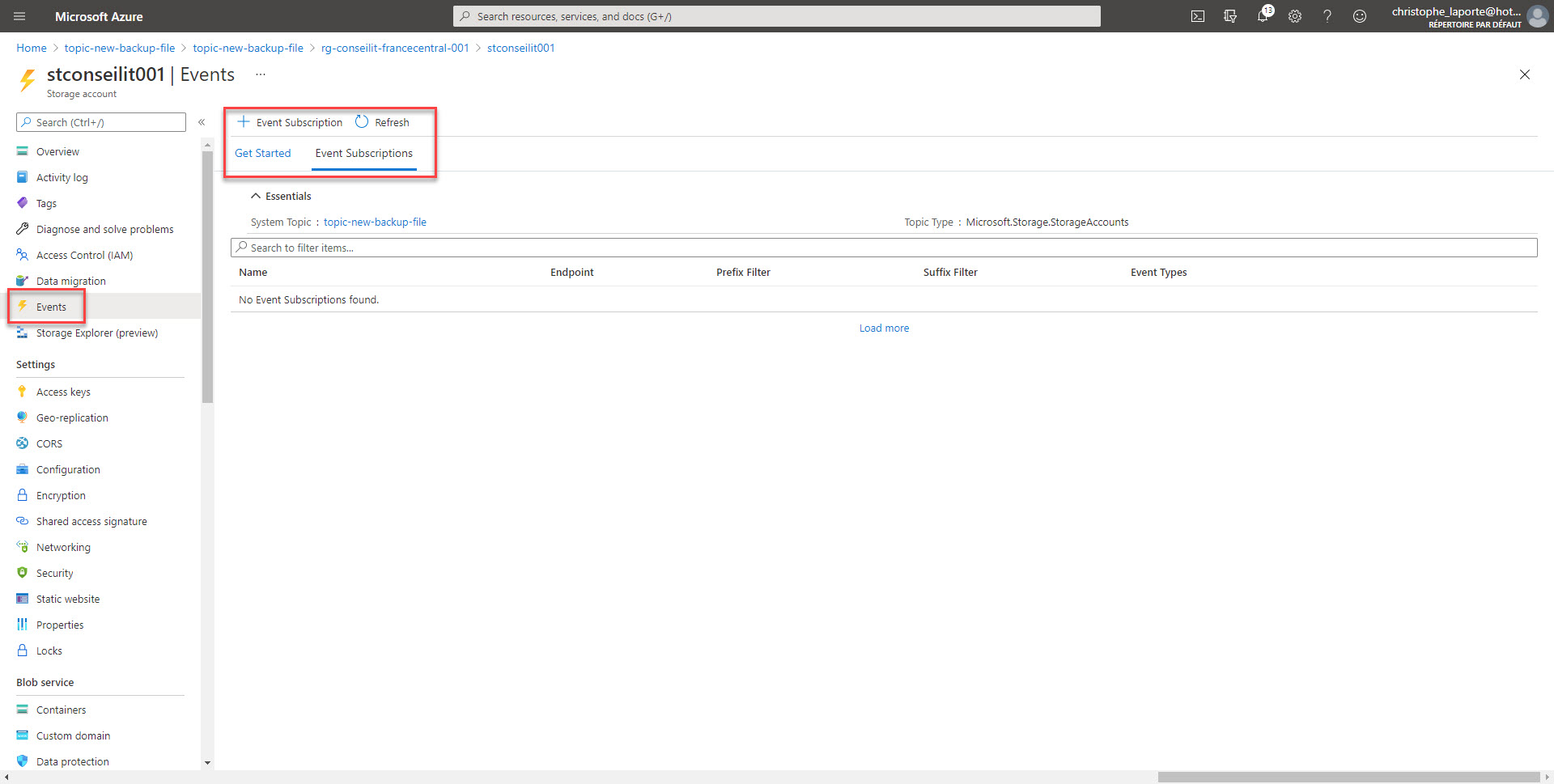
Okay, nous sommes proches de la fin … Il faut à présent créer un Topic système et créer un abonnement
Pensez à filtrer les évènements pour ne conserver que les « Blobs Created » et configurez le WebHook avec l’URL préciseument mise de côté lors d’une précédente étape.
Comme dit précédement, l’idée n’est pas d’activer le runbook lors de la création d’audit, ou bien de xEvents, c’est pour cela que nous allons filtrer en fonction du sujet avec le conteneur sql-backup.
Et afin de ne pas déclancher d’évènement multiples lors de la création d’un backup, nous allons mettre un filtre avancé avec « data.api » contains « PutBlockList ». En fait cette API est appelée en fin de sauvegarde une fois tous les Blocks ( API « PutBlock ») écrits. N’hésitez pa sà faire appel à votre moteur de recherche favori pour de plus amples détails sur le mode de fonctionnement.
Il ne reste à présent plus qu’à tester la solution …
Côté SQL Server, nous créons le credential et démarrons une sauvegarde complète des bases système.
Après quelques secondes, nous pouvons constater que des répertoires sont apparus dans le container, avec un sous répertoire « FULL » contenant la sauvegarde de chacune des bases.
Si l’on bascule sur le RunBook, nous constatons que des exécutions ont été faites, correspondant à chaque fichier de backup déposé.
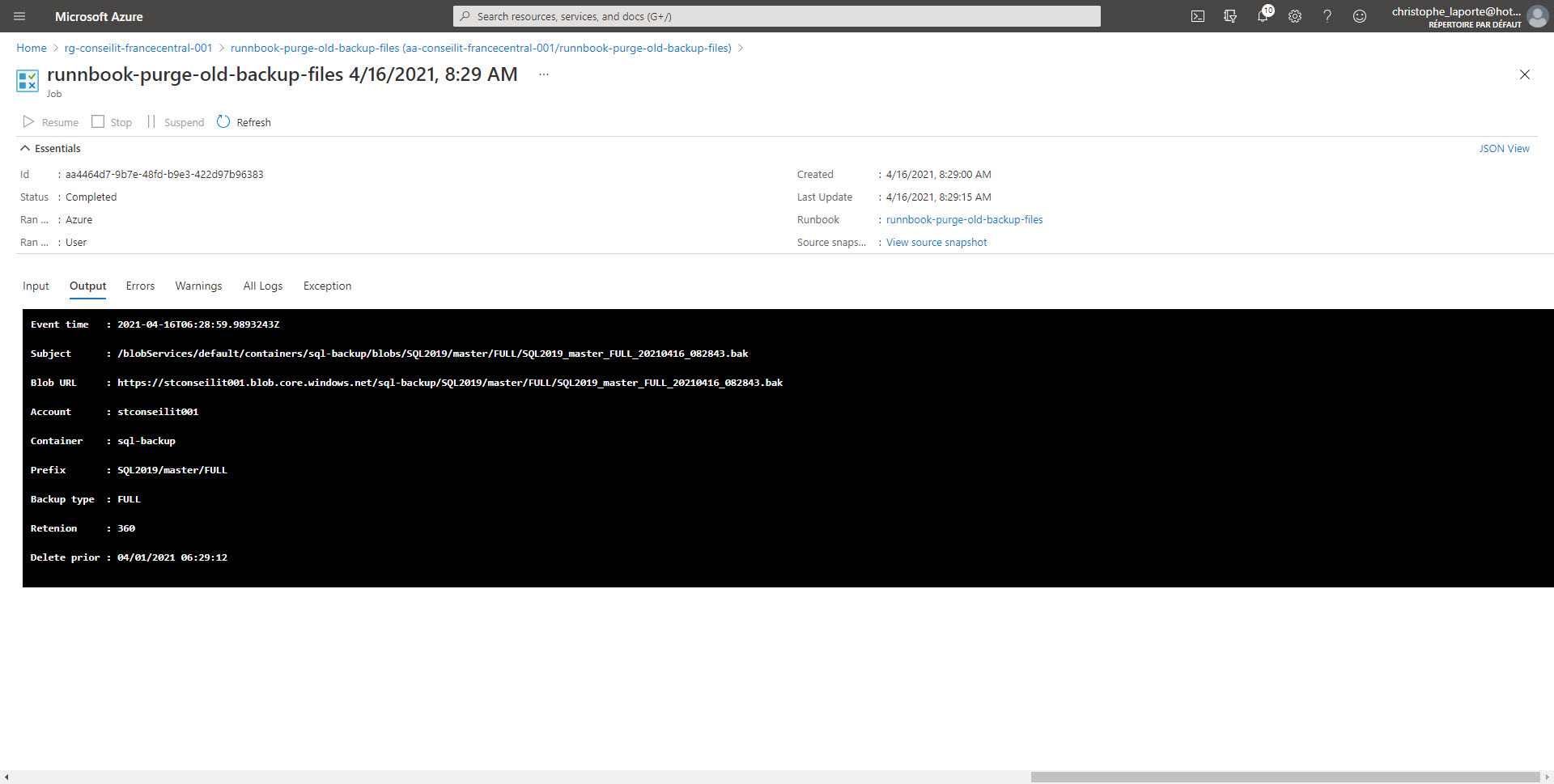
Il est possible de sélectionner une exécution et de visualiser la zone Output, qui contient les données issues des lignes write-output du code PowerShell.
Lorsque vous aurez dépassé la durée de rétention configurée dans vos variables, la liste des fichiers devant être supprimée s’affichera alors.
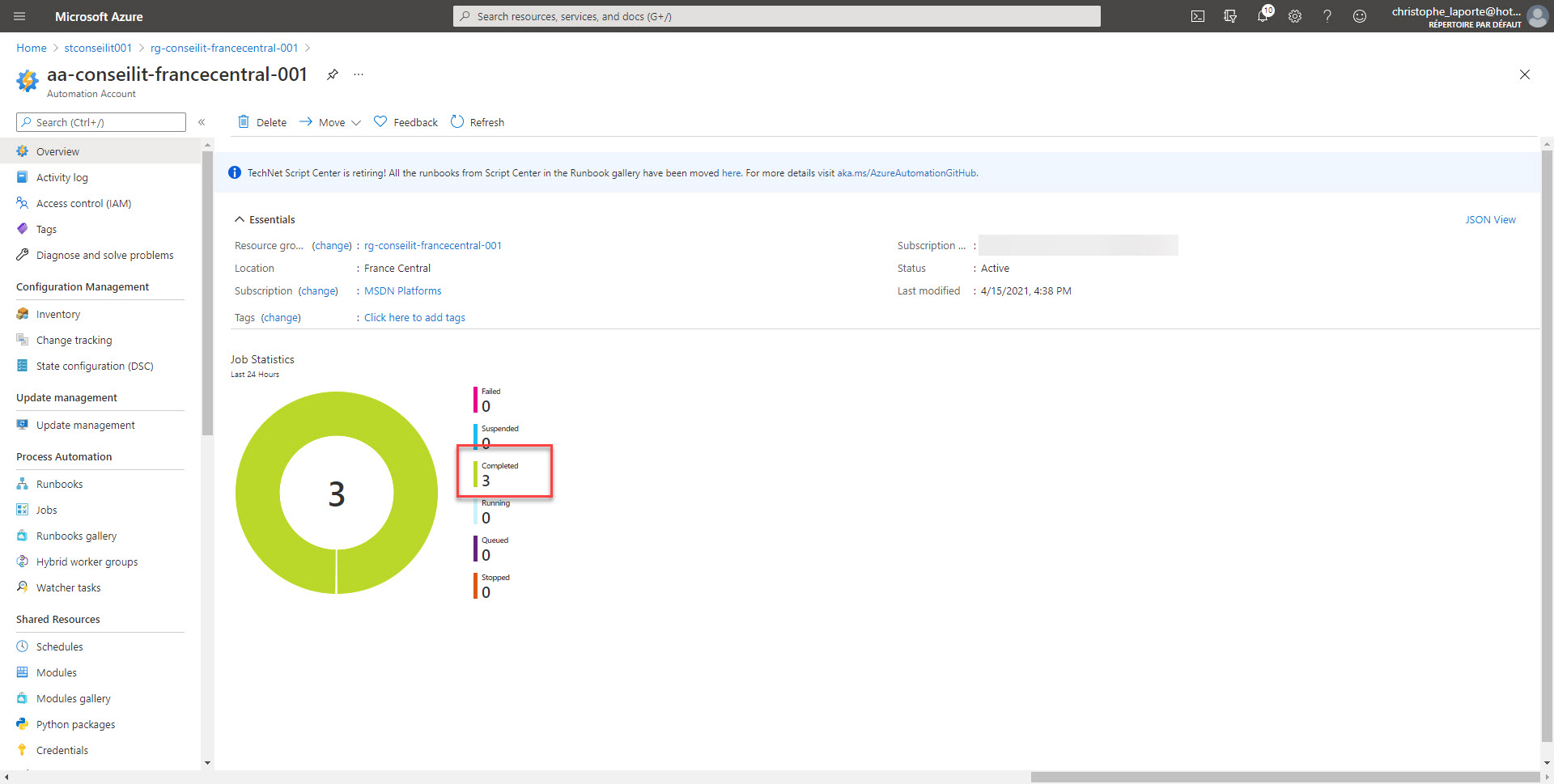
Des statistiques d’exécution sont disponibles à la fois au niveau de l’event subscriptions sur le compte de stockage, tout comme sur le compte d’automatisation.
Cette solution m’a paru être relativemetn simple à mettre en place, tout en offrant des garanties sur la rétention des fichiers, même en cas de problème au niveau des backups (pas de backup -> pas de déclanchement de la purge pour ce type de sauveagrde et pour cette base).
En fonction des cas, un simple Life Cycle Management pourrait suffire, par exemple au-delà de 30 jours déplacement des fichiers vers du stockage froid, puis au-delà de 180 jours suppression sur le stockage froid …. A vous de voir en fonction de votre politique de rétention et de votre PRA.