L’actualité récente a rappelé à certaines sociétés, institutions ou associations, que le « cloud » n’est rien d’autre que des serveurs hébergés dans un « autre » datacenter. Datacenter qui est sujet à des pannes voire des incendies.
Petite note pour ceux qui voudraient critiquer OVH rapport à l’incendie survenu dans le datacenter à Strasbourg : AWS a subit un désastre de ce type en Aout 2018 au Japon. Et il doit y avoir d’autres exemples que je n’ai plus en tête.
Le métier de DBA évolue du fait du déplacement des ressources vers le « cloud », mais ne devient pas moins intéressant (il y a un certain désamour pour la profession) ou crucial (oui, la data c’est le pétrole de demain et les applications passent mais les données restent).
L’installation et la configuration système et SQL Server a bien évolué. Mais la problématique reste la même, au lieu de choisir du matériel, nous devons composer avec les différentes offres PaaS et IaaS, jongler également avec les coûts …
Le capacity planning est plus simple en revanche, car opter pour un tiers inférieur, supérieur, voire du serverless offre une latitude et une simplicité impensable lors mes débuts dans ce métier au siècle dernier.
Le backup / restore est facilité par l’adoption du cloud (stockage quasi illimité voire service managé), certes, mais les notions de RPO et RTO sont toujours d’actualité, alors pensez à tester votre restore pour mesurer votre temps maximal d’disponibilité.
Le design d’une base de données, l’optimisation, l’indexation sont d’autant plus important car non seulement cela aura un impact sur la performance de l’application et la satisfaction des utilisateurs, mais en outre, cela aura également un impact direct sur le coût du hosting.
Parmi les tâches du DBA, on retrouve également la disponibilité des bases de données, et donc la redondance de zone, redondance géographique, mais également, les problématiques liées à la sécurité ainsi qu’à la régulation (RGPD …).
L’actualité a fait une piqure de rappel cinglante : la nécessité de disposer d’un PRA et de le tester.
Mon conseil à présent : pensez également à vous munir d’un DBA ! Oui, je prêche pour ma paroisse, mais reportez vous à mon article prémonitoire sur la disponibilité des données … Mieux vaut s’en préoccuper avant !
Un DBA en temps partagé peut constituer la solution idéale pour un grand nombre de sociétés (PME, PMI voire grande entreprise).
Il y a quelques temps, je publiais un article sur la nécessite de se préoccuper de la haute disponibilité de SQL Server sur un cloud public tel qu’Azure. Et plus largement, la question de la redondance des services lorsque l‘on utilise des services managés.
Globalement, la réponse était Oui, il faut s’en préoccuper.
Malheureusement, l’actualité m’aura donné raison, trop tôt probablement pour certains qui auraient songé à modifier leur infrastructure.
Je ne vais pas tirer sur l’ambulance, j’apprécie OVH pour certains de leurs services que j’ai utilisé par le passé, que j’utilise encore pour certains, mais il manque encore une brique à l’édifice.
Aucun hébergeur n’est prémuni contre tous les risques, j’ai déjà écrit cette phrase dans l’article précédent. Il est donc nécessaire de prévoir son propre PRA / DRP au cas où les service fournis par le Cloud Provider ne vous paraissent pas suffisamment protégés.
Pour reprendre le tweet du fondateur d OVH, il était temps d’activer le DRP … Le votre …
Bien m’sieur, compris.
Mais encore faut-il pouvoir …
La console de gestion n’est toujours pas disponible à l’heure où cet article est écrit, soit plus de 8 heures après le début du sinistre. Bref, l’histoire n’est pas complète si les services basculent mais le switch d’un IP Failover ne permet pas d’atteindre ses services.
Pour la petite histoire, d’un point de vue SQL, la bascule s’est bien passée pour mon client, mais il a fallu en urgence revoir les chaines de connexion car l’IP failover était défaillant.
La redondance des services est une chose, la redondance des outils de gestion en est une autre.
Besoin d’audit ou de conseil ? Vous savez où me trouver …
Si vous suivez ce blog, il ne vous aura pas échappé qu’une partie conséquente de mon activité de consultant indépendant est liée à la haute disponibilité de SQL Server. Que ce soit sur des machines physiques ou virtuelles, dans vos datacenters ou bien externalisé, voire hébergées sur un cloud public, la disponibilité de votre instance, de votre base ou bien d’une table revêt toute son importance … quand vous ne pouvez pas y accéder.
C’est un exercice très compliqué à réaliser, mais il est fondamental de quantifier l’indisponibilité de votre instance ou de votre base. Beaucoup de questions à se poser, j’utilise cette diapositive lors de mes formations et interventions, pour obtenir un maximum d’information. Une grande partie des réponses est issue du Business, côté technique on doit s’adapter.
Une fois l’indisponibilité quantifiée, en $ ou €, vous êtes en mesure de décider s’il est rentable / important de mettre en HA votre base de données, car la HA a forcément un coût, ainsi qu’un impact potentiel sur la performance de l’application.
OnPrem, ou bien en IaaS sur un cloud public, vous avez donc le choix entre du Cluster de Basculement ou bien des Groupes de Disponibilité. Je parle de HA, donc exit le Log Shipping qui est une solution de Disaster Recovery. En fonction de la granularité de protection, de la nécessité de disposer d’un RPO nul, d’un RTO très faible, de modèle de récupération simple, vous allez choisir entre du FCI ou AGs.
Sur le un Cloud Public tel qu’Azure, le problème se corse, car le niveau de service (SLA) promis est déjà élevé, généralement au moins de 99.9% voire 99.995%.
Ce qui, reporté au fameux tableau des « Nine », nous donne une indisponibilité annuelle comprise entre 52 minutes et 26 minutes pour un niveau de service General Purpose / Standard / Basique …. Est-ce suffisant ? Probablement dans une très grande majorité de cas.
Il faut bien faire la différence entre disponibilité et Uptime. L’OS et SQL Server peuvent être Up and Running, mais la disponibilité comprend également la capacité d’accéder à une donnée dans un temps imparti : par exemple, tel select doit se faire en x millisecondes ou secondes. On entrevoit donc l’impact sur la disponibilité d’un plan de maintenance qui reconstruit des index cluster sur une édition standard : le rebuild est offline ! Le tableau nous parles certes de disponibilité, mais globalement cela couvre Hardware+Network+OS+Service SQL.
On vous garanti l’accès à la donnée, ce que vous en faites est une autre histoire. Si vous avez des locks ou des performances qui ne sont pas au niveau attendu, cela n’est pas couvert par le SLA.
Mais ….
Que se passe t’il si votre base devient inaccessible durant …. 11 heures ? Les provider cloud ne sont pas a l’abris de tout problème, ils essaient seulement de prendre en considération plus de risque que vous dans votre Datacenter et s’en protègent du mieux qu’ils peuvent. Cependant, l’imprévu est toujours possible.
Imaginez que, le Lundi 14 septembre 2020, à compter de 13h30, votre base soit injoignable, et ce jusqu’à 00h41 le 15/09 … C’est ce qu’il s’et passé, sur la région UK South … Et ce n’est pas une seule base qui a été impacté, mais la connectivité globale de la région ! 11 heures d’indisponibilité, malgré la promesse d’un SLA de 99,99 %.
Microsoft n’est pas le seul cloud provider à avoir expérimenté de tels problèmes…
Il est donc important de ne pas se fier totalement au SLA annoncé et conserver les réflexes de haute disponibilité… D’un point de vue Azure, cela se traduit par des services redondants à l’intérieur d’une région (Availability Zones) voire inter régions (Regions pairs : France Central + France Sud par exemple).
Traduit pour SQL Server en mode PaaS, cela se présente sous forme de Géo-Réplication, Failover Groups et redondance de zone, ce dernier point étant encore en preview. Je ne traite pas le cas de la Managed Instance, mais sachez que la redondance de zone et les groupes de basculement automatiques sont disponibles.
Chacune de ces fonctionnalités a ses avantages et inconvénients. Le slide suivant, que j’utilise lors des formations, permet de visualiser rapidement les principales différences entre la géo-réplication et les groupes de basculement automatiques.
Je ne vous cache pas que le fait de disposer d’un failover automatique et d’une chaine de connexion inchangée pour un ensemble de bases me fait préférer le failover group. Mais il reste limité à 1 seul réplica secondaire, qui est cependant accessible en lecture seule pour offloader le reporting par exemple. Vous aurez reconnu un groupe de disponiblité, et, effectivement, les failover groups en sont dérivés.
Comme dit précédemment, la HA peut avoir un coût. La géo réplication tout comme les failover groups nécessitent la création d’une base ou d’un pool élastique. Il y a un coût additionnel.
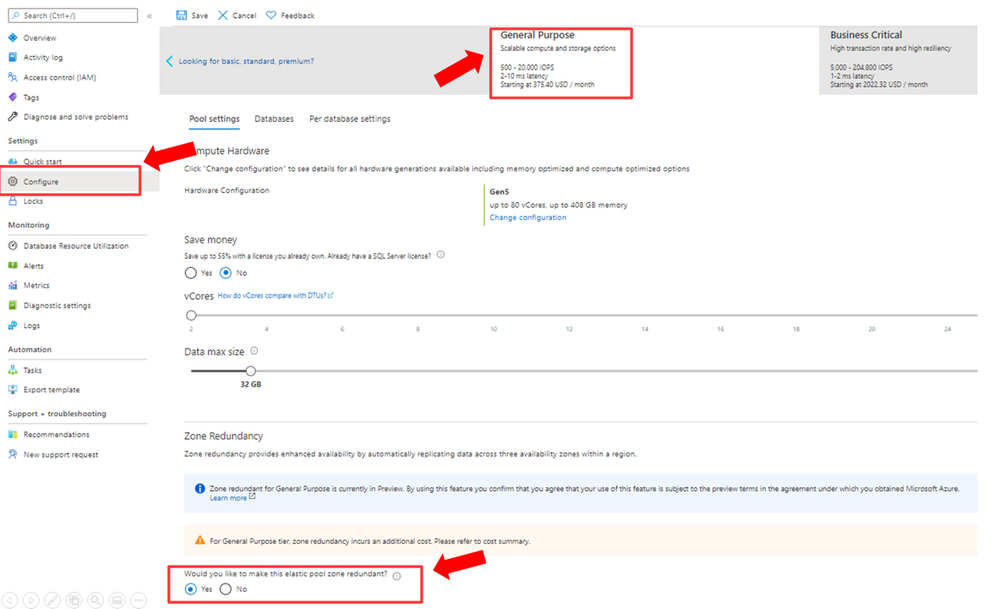
Si vous n’avez pas besoin d’un réplica en lecture seule mais que vous souhaitez disposer d’une solution de continuité d’activité en niveau de service General Purpose, alors la redondance de zone est faite pour vous.
Sachant qu’en niveau General Purpose, le compute et le storage sont séparés, il est alors simple de déposer les fichiers MDF/LDF sur un stockage géographiquement redondant : des disques Azure Premium Storage ZRS (Zone Redundant). Ainsi en cas de problème sur une zone, une bascule automatique de zone sera effectuée. Si votre application suit les mêmes règles de disponibilité, par exemple vos VMs dans 2 ou 3 availability zones, la continuité de service est assurée.
Je ne l’ai pas encore mentionné mais la redondance de zone est également disponible sur les pools élastiques.
La capture montre le SLO General Purpose, mais cette option est bien entendu également disponible en Business Critical, bien qu’implémentée techniquement de manière différente car le BC utilise un stockage local SSD.
L’incident UK South donné en exemple ne concernait qu’une seule zone, en utilisant ce principe, notre base de données n’aurait subi qu’une légère perte de service, le temps de basculer les ressources vers la seconde zone.
Conclusion : oui, il faut encore se préoccuper de la haute disponibilité, même lorsque l’on est hébergé sur un cloud public.
Tout DBA se doit de disposer d’une boite à outil prête à l’emploi pour répondre le plus rapidement à une série de problèmes susceptibles de se produire.
Combien de fois vous a-t-on demandé de restaurer une base de données ? Rapidement, très rapidement, car la prod est plantée. Ou bien restaurer la base de production vers l’environnement d’intégration. Ou encore restaurer une copie de base de données à un point précis dans le temps, histoire de vérifier les données à ce moment (alors que la fonctionnalité Temporal Table est disponible – je dis ça je ne dis rien …). Ce n’est pas à ce moment-là qu’il faut se poser des questions sur comment faire. Utiliser ou non l’assistant fourni dans SSMS …
Pour rappel, l’assistant SSMS vous permet de faire un restaure Database de manière très simple. Deux sources possibles : l’historique des sauvegardes et un device, un backup en fait.
J’avoue que je ne suis pas fan de cette option. Et pour plusieurs raisons. La première : l’assistant utilisé avec l’historique des sauvegardes est inopérant lorsque votre base est mise en HA dans un groupe de disponibilité. Les backups peuvent s’effectuer sur le réplica primaire, tout comme n’importe lequel des secondaires (je ne vais pas rentrer dans le détail de FULL COPY_ONLY et des DIFF). Mais la base MDSB n’st pas (encore) « répliquée » sur tous els réplicas d’un AG. Donc l’assistant devient inutilisable.
Tout comme il est inutilisable si vous avez « oublié » de purger les historiques et que SSMS doit scanner la table Backupset sur 10 ans d’historiques ….
Pour contrer ce genre de problèmes, on peut utiliser la notion de Device en tant que source, autrement dit des fichiers de sauvegarde. Vous pouvez ainsi sélectionner 1 ou N fichiers, voire tous les fichiers d’un répertoire, et SSMS va effectuer des RESTORE HEADERONLY et RESTORE FILELISTONLY pour reconstituer la bonne séquence de restauration. Il m’est fréquemment arrivé de crasher SSMS lorsque des centaines de fichiers sont concernés (imaginez juste un backup toutes les minutes, sur 1 semaine …).
Donc encore une fois, le jour où cela se produit et que vous n’avez pas de plan B, vous risquez de suer à grosses gouttes …
C’est pour cela que depuis des années j’avais construit des scripts PowerShell de restaure de base, avec toutes les options imaginables pour me simplifier la vie.
Et puis dbaTools est arrivé, en proposant une commande restore-dbaDatabase … J’ai donc jeté une partie de mes scripts pour basculer sur ce cmdlet.
Restaurer plusieurs bases de données sur une même instance, par exemple depuis le serveur de production vers le serveur d’intégration peut être extrêmement chronophage, surtout si vous avez des dizaines, voire des centaines de bases à traiter. La commande ci-dessous vous permet de restaurer toutes les bases contenues dans les backups présents dans un répertoire et de déplacer les fichiers de DATA et LOG au moment du restore, l’option MOVE TO, pour parer à des éventuelles différences de structure disque entre les serveurs source et destination.
# List of backup files
$backupPath = "\\Rebond\backup\MultipleDatabases"
Get-ChildItem -Path $backupPath
# Restore multiple databases at once - the quickest way
Restore-DbaDatabase -SqlInstance SQL15AG1 `
-Path $backupPath `
-UseDestinationDefaultDirectories
# list databases
get-dbaDatabase -SqlInstance SQL15AG1 -ExcludeSystem | format-table -autosize
Parfois on est amené à effectuer une restauration d’une base vers plusieurs instances. Le script suivant permet à la fois de déplacer les fichiers sur des emplacement spécifiques, mais aussi d’obtenir les scripts de restauration, avant de l’exécuter sur différentes instances.
Et enfin un dernier exemple qui permet de restaurer une copie d’une base de données à un point précis dans le temps, en ajoutant un préfixe au nom de la base ainsi qu’aux fichiers. On présume également que la structure des dossiers de sauvegarde suit la solution de maintenance de Ola Hallengren.
# Restore a copy of a database at a specific point in time
$BackupPath = "\\Rebond\backup\AdventureworksLT"
Get-ChildItem -Path $backupPath -Recurse -Directory # looks like OH folder structure 🙂
Get-ChildItem -Path $backupPath -Recurse
$RestoreTime = Get-Date('16:20 20/02/2021')
$RestoredDatabaseNamePrefix = $RestoreTime.ToString("yyyyMMdd_HHmmss_")
$Result = Restore-DbaDatabase -SqlInstance SQL15AG1 `
-Path $BackupPath `
-UseDestinationDefaultDirectories `
-MaintenanceSolutionBackup `
-RestoredDatabaseNamePrefix $RestoredDatabaseNamePrefix `
-DestinationFilePrefix $RestoredDatabaseNamePrefix `
-RestoreTime $RestoreTime `
-WithReplace
$Result | Select-Object Database, BackupFile, FileRestoreTime, DatabaseRestoreTime | Format-Table -AutoSize
Write-Host "Time taken to restore $($Result[$Result.count - 1].Database) database : $($Result[$Result.count - 1].DatabaseRestoreTime) ($($Result.count) files)"
# list databases
get-dbaDatabase -SqlInstance SQL15AG1 -ExcludeSystem | format-table -autosize
Bref, vous aurez compris qu’au travers de quelques lignes de code extrêmement simples vous pouvez restaurer des bases de données comme vous le souhaitez sans vous soucier du « bon » fonctionnement de SSMS.
Si vous administrez un tant soit peu un serveur SQL, il vous est probablement arrivé de devoir traiter d’une problématique de DeadLock.
pour mémoire, le DeadLock est le stade utile d’un situation de verrouillage où il n’existe pas de solution car chacun des processus impliqués attend que l’autre se termine afin de pouvoir continuer son traitement. L’histoire du serpent qui se mort la queue pour faire simple.
Dans des version « préhistoriques » de SQL Server, on faisait appel à des Trace Flags afin d’enregistrer els informations dans le fichier errorlog, afin de pouvoir comprendre et dépanner ces sutuations.
Avec l’arrivée des xEvents, et principalement de la sessionSystem_health, nul besoin des TF 3605, 1204 et 1205. Par défaut tout est enregistré ….
Voici le bout de code que je vais utiliser afin de provoquer le dead lock sur la base AdventureWorks
-- Session 1
Use AdventureWorks
GO
BEGIN TRAN
update Production.Product
set name = 'Session 1 - Product 722'
where ProductID = 722
-- Session 2
Use AdventureWorks
GO
BEGIN TRAN
update Production.Product
set name = 'Session 2 - Product 512'
where ProductID = 512
-- Session 1
update Production.Product
set name = 'Session 1 - Product 512'
where ProductID = 512
A ce stade, rien de particulier, simple situation de blocage, il suffit qu’une des session fasse un COMMIT ou un ROLLBACK, les verrous seront levés et donc la seconde session pourra se terminer normalement. La commande UPDATE de la session 1 est bloquée par l’update de la session 2. Le verrou Exclusif de la session 2, qui a été posé sur l’enregistrement 512 est incompatible avec le verrou exclusif demandé par la session 1 sur ce même enregistrement.
Tout se complique lorsque la session 2 veut accéder à la ressource qui est déjà verrouillée par la session 1, l’enregistrement 722.
-- Session 2
update Production.Product
set name = 'Session 2 - Product 722'
where ProductID = 722
La situation est inextricable, car chacune des sessions attend que l’autre ait terminé pour se terminer. SQL Server doit prendre une décision et tuer un des processus.
le xEvent System_Health enregistre l’évènement dans le ring buffer et dans un fichier xel afin de résister à un restart de SQL Server.
L’onglet Deadlock nous permet de visualiser la situation :
Si l’on s’attarde avec la souris sur les processus, on peut visualiser les requêtes mises en cause. Dans notre exemple, le deadlock est simple, mais il peut arriver que le nombre de process impliqués soit plus important. La requête nous renseigne sur les ressources lockées, mais si cela se produit avec des index noncluster (ah….les index avec colonne incluse et les index composites …), le troubleshooting est un peu plus complexe.
En creusant un peu, toutes les informations sont présentes afin de découvrir quels sont les enregistrements impliqués. Nous allons donc décoder les informations renvoyées.
Nous allons nous plonger dans la version XML du deadlock.
Nous allons nous intéresser à la propriété WaitRessource qui détient la clé (sans jeu de mot !) du problème.
La base de données N°5 correspond effectivement au numéro de la base AdventureWorks.
L’information suivante est un HOBT (Heap or BTree). Et l’on retrouve notre table Production.Product.
SELECT c.name as schema_name,
o.name as object_name,
i.name as index_name,
p.object_id,p.index_id,p.partition_id,p.hobt_id
FROM sys.partitions AS p
INNER JOIN sys.objects as o on p.object_id=o.object_id
INNER JOIN sys.indexes as i on p.index_id=i.index_id and p.object_id=i.object_id
INNER JOIN sys.schemas AS c on o.schema_id=c.schema_id
WHERE p.hobt_id = 72057594045136896;
Bon, OK, trouver la table n’était pas vraiment compliqué.
On va faire appel à une commande magique afin de trouver les enregistrements impliqués dans le Deadlock. Il suffit de recopier la valeur entre parenthèses de la propriété WaitRessource que nous allons appeler KeyHashValue.
Grâce à la fonction non documentée %%lockres%%, il devient simple de retrouver les enregistrements concernés.
On retrouve par ailleurs cette information lorsque l’on visualise les données de la page via DBCC PAGE.
Grâce à une seconde fonction magique, sys.fn_physlocFormatter, nous pouvons retrouver quelle datapage contient l’enregistrement en question. Nous allons nous focaliser sur le productID 512 qui est donc présent dans la page 788 du fichier n°1, à l’emplacement 0.
Je ne vais pas détailler dans ce post les information renvoyées par DBCC PAGE, la partie Header en particulier. Ensuite, on va trouver les enregistrements, donc l’enregistrement slot 0. Attention, Slot 0 ne signifie pas forcément le premier enregistrement de la datapage, il faut se référer au tableau d’offset en bas de page pour connaitre à quel emplacement retrouver l’enregistrement.
On retrouve la valeur KeyHashValue qui était présente dans le xml_deadlock_report. Nous somme donc bien sur l’enregistrement qui est impliqué dans le verrou. Enregistrement d’un index cluster, les données donc, ou bien d’un index non cluster, cela ne changerait rien.
Il suffit de procéder de même avec le second enregistrement pour terminer la résolution de cet incident.
Pour les adeptes du journal de transactions, il est possible d’y retrouver les informations de verrouillage directement. Il est possible de visualiser le contenu du journal actif avec fn_dblog() ou bien dans une sauvegardes au travers de fn_dump_dblog().
Si l’on repart des transactions, identifiées par les paramètres xactid dans le xml_deadlock_report, il est possible de retrouver les mêmes informations.
SELECT [Operation],[Context,SPID],[Transaction SID],[Xact ID],[Transaction ID],[Page ID],
[Slot ID],AllocUnitName,[Lock Information],[Begin Time],[End Time]
FROM sys.fn_dblog(null,null)
WHERE [Transaction ID] in (
SELECT [Transaction ID]
FROM sys.fn_dblog(null,null)
WHERE [Xact ID] IN (246372,246434)
)
On retrouve les numéros de page dans lesquelles trouver les enregistrements, notée en hexadécimal, 314 et 318 correspondant respectivement aux valeurs 788 et 789. On retrouve ensuite la propriété KeyHashValue dans la colonne LockInformation.
Au passage, si vous souhaitez savoir qui a passé la commande, la colonne [Transaction SID] correspond au SID que vous trouvez dans server_principal et/ou database_principal.
Au travers de quelques lignes de code il a été relativement simple de déterminer quels étaient les enregistrements impliqués dans un deadlock.
Comment éviter cette situation d’interblocage ? Cette fois, la réponse est loin d’être simple. Peu de possibilités côté DBA : on peut essayer de positionner des index nonclustered afin de permettre à SQL Server d’accéder aux enregistrements de manière différente, mais rien de garanti. On peut faire usage du RCSI ou bien du niveau d’isolation SNAPSHOT, mais cela peut aussi changer le comportement de l’application. Généralement, le problème se situe au niveau du code client, accéder aux tables dans le même ordre, limiter au maximum la durée et les ressources consommées par les transactions, éviter toute interaction utilisateur durant une transaction.
Pensez également à bien clore vos transactions, durant mes audits, je constate malheureusement trop souvent des sessions sleeping durant des heures avec des transactions ouvertes. Là, désolé, je ne peux plus rien faire pour vous. Toutes les actions en base de données doivent être réalisées de la sorte: – Ouvrir une connexion – Optionnellement créer une transaction – Exécuter la requête – Si une transaction a été ouverte, COMMITER ou ROLLBACKer la transaction – Fermer la connexion.
Le pool de connexion se chargera de maintenir la connexion ouverte pour être réutilisée. A cela pensez à ajouter une logique de Retry, avec un délai constant ou croissant entre chaque tentative et vous vous rapprochez des bonnes pratiques.
L’utilisation de PowerShell est devenu un standard de l’administration, y compris pour les DBAs.
L’installation de SQL Server peut se faire via l’utilisation d’un assistant graphique, mais également via la ligne de commande setup.exe. Pour mémoire, l’assistant graphique n’est qu’un super éditeur de fichier texte car une fois que vous avez parcouru tous les écrans de l’assistant, un fichier configuration.ini est généré afin de rappeler setup.exe avec le paramètre /configurationfile. Très pratique lorsque l’on souhaite répéter un certain nombre de fois la même installation.
Pour ma part, je travaille principalement avec la ligne de commande, on va dire que c’est historique !
Voici un bout de code que j’utilise régulièrement :
D’un point de vue PowerShell strict, rien de neuf quant à l’installation de SQL Server. Mais la communauté, au travers des modules dbaTools, a créé un cmdlet pour « simplifier » le process d’installation. Lorsque ‘l’on a travaillé des années en ligne de commande, le côté « simple » n’apparait pas immédiatement, je l’avoue.
Mais la commande Install-DbaInstance offre l’avantage de pouvoir effectuer la même installation sur plusieurs serveurs simultanément, sans effort supplémentaire.
En toute honnêteté, je n’ai pas encore opté systématiquement pour cette méthode d’installation, mais lorsque je dois installer plusieurs serveurs de test de manière identique pour des formation de type haute disponibilité, par exemple un cluster Always On Availability Group X nœuds, je fais appel à Install-DbaInstance.
# Source reporsitory configuration
Set-DbatoolsConfig -Name Path.SQLServerSetup -Value '\\rebond\sources'
# my super secure sa password for demos
$Username = 'sa'
$Password = 'Password1!'
$pass = ConvertTo-SecureString -AsPlainText $Password -Force
$saCred = New-Object System.Management.Automation.PSCredential -ArgumentList $Username,$pass
# the credential used to install SQL Server on the remote computers
$CurrentUser = [System.Security.Principal.WindowsIdentity]::GetCurrent().Name
$InstallCred = Get-Credential -Message "Enter current user and password to connect remote computer" -UserName $CurrentUser
# some configuration stuffs
$config = @{
AGTSVCSTARTUPTYPE = "Automatic"
SQLCOLLATION = "Latin1_General_CI_AS"
BROWSERSVCSTARTUPTYPE = "Manual"
FILESTREAMLEVEL = 1
INSTALLSQLDATADIR="G:"
SQLBACKUPDIR="G:\MSSQL15.MSSQLSERVER\Backup"
SQLUSERDBDIR="G:\MSSQL15.MSSQLSERVER\MSSQL\Data"
SQLUSERDBLOGDIR="H:\MSSQL15.MSSQLSERVER\Log"
SQLTEMPDBDIR="T:\MSSQL15.MSSQLSERVER\Data"
SQLTEMPDBLOGDIR="U:\MSSQL15.MSSQLSERVER\Log"
}
# Perform the installation
Install-DbaInstance -SqlInstance SQL15AG1,SQL15AG2 `
-Credential $InstallCred `
-Version 2019 `
-Feature Engine,Replication,FullText,IntegrationServices `
-AuthenticationMode Mixed `
-AdminAccount $CurrentUser `
-SaCredential $saCred `
-PerformVolumeMaintenanceTasks `
-SaveConfiguration C:\InstallScripts `
-Configuration $config `
-Confirm:$false
# Connect using Windows authentication
$Servers = Connect-DbaInstance -SqlInstance SQL15AG1,SQL15AG2
$Servers | Select-Object DomainInstanceName,VersionMajor,Edition
# Connect using SQL authentication
$Servers = Connect-DbaInstance -SqlInstance SQL15AG1,SQL15AG2 -SqlCredential $saCred
$Servers | get-dbaDatabase | format-table -autosize
L’utilisation de la commande requiert de disposer d’un partage réseau hébergeant les sources de SQL Server. La commande va chercher récursivement le « bon » répertoire, correspondant à la version que vous souhaitez installer. De même, si vous disposer des Cumulative Updates, une installation SlipStream est possible.
Un certain nombre de paramètres d’installation sont accessibles directement depuis les paramètres de la commande. pour d’autres, il faut se tourner vers une variable de configuration qui reprend les items de la ligne de commande setup.exe
Je trouve cependant deux points très bien pensés pour ce module: – La possibilité de spécifier plusieurs instance à installer (et cela fonctionne également pour des instances nommées) – La possibilité d’enregistrer localement, sur la machine de rebond, le fichier INI correspondant à l’installation, cela peut servir …
L’utilisation de PowerShell est devenu un standard de l’administration, y compris pour les DBAs. Certes il existe des cmdlets natifs pour SQL Server, mais la bibliothèque dbaTools, projet communautaire, est devenu un incontournable et indispensable outil que tout DBA se doit de connaitre.
Cette courte vidéo est en fait une introduction pour une série d’articles et vidéos à venir sur les commandes PowerShell liées à la bibliothèque dbaTools.
Ci dessous le code utilisé lors de cette vidéo pour l’installation du module dbaTools.
Plus tôt dans la journée j’au publiée une petite vidéo au sujet de cette fonction méconnue de SQL Server : la durabilité retardée, ou Delayed Durability.
Lors des audits de performance que je mène chez mes clients, l’attente de type WRITELOG est une des attentes les plus fréquemment rencontrée. Cette attente est liée à la difficulté que rencontre SQL Server pour écrire les transactions dans le fichier LDF, le fameux journal des transactions.
Lorsque je suis d’humeur joueuse, je propose alors à mon client de tirer au sort els transactions qui seront autorisées à écrire dans le journal de transaction, et donc à satisfaire au « D » de « ACID » (Atomicité, Consistance, Isolation et Durabilité). Car en effet, le sous-système disque, principalement le volume qui héberge le journal de transactions doit avoir la capacité de supporter les IOs demandés par SQL Server, sous peine de provoquer de sérieux ralentissements. L’écriture dans le journal étant synchrone, tant que la transaction n’a pas été persistée dans le fichier LDF, souvenez vous que l’on fonctionne sous régime de WAL (Write Ahead Logging), il n’est pas possible de rendre l amain à l’application.
Donc lorsque le volume qui supporte le journal de transaction est la source des problèmes de performance, il n’existe que peu de solutions, mis à part l’augmentation de performance hardware … Sauf à soulager les IOs, d’où la blague qui consiste à tirer au sort les transactions autorisées à perdurer. Mais l’idée n’est pas farfelue pour autant car il suffit parfois de jeter un œil aux statistiques d’usage des index pour se rendre compte à quel point certains sont inutiles. Or, à chaque INSERT, UPDATE ou DELETE, l’index va lui aussi être modifié et générer une entrée dans le journal de transaction …
L’exemple suivant est assez flagrant, une table comportant plusieurs index noncluster supporte une charge conséquente en écriture, mais jamais les index sont utilisés pour la lecture …
Diminue les IOs, et donc la pression sur le journal de transaction peut être censé. Par exemple, Hekaton propose de type de fonctionnements. En effet le stables InMemory dans SQL Server permettent une durabilité de type SCHEMA_ONLY, autrement dit, on n’écrit JAMAIS dans le journal de transactions, seule la structure de la table est persistante. Il est possible d’utiliser ces tables « Temporaires » dans bien des cas.
Mais qu’en est-il pour les tables de type Row Disk Based, par opposition à InMemory. On ne va pas enregistrer une transaction sur 2, on est bien d’accord. Et contrairement à des problématiques de PAGEIOLATCH qui peuvent être amoindries par un ajout de mémoire, l’augmentation de capacité du BUFFER POOL ne changera rien à la donne si vous souffres d’attente de type WRITELOG.
Il faut donc se tourner vers une fonctionnalité méconnue apparue avec SQL Server 2014 qui permet d’opter pour une durabilité retardée. En fait, rendre l’IO d’écriture dans le journal de transaction asynchrone, et donc permettre à l’application de poursuivre le traitement sans attendre l’écriture physique sur disque.
Ci-dessous el bout de code m’ayant servi lors de démos :
USE MASTER
GO
DROP DATABASE IF EXISTS [DemoDelayedDurability];
CREATE DATABASE [DemoDelayedDurability];
GO
USE [master]
GO
ALTER DATABASE [DemoDelayedDurability] SET RECOVERY SIMPLE WITH NO_WAIT
GO
ALTER DATABASE [DemoDelayedDurability]
MODIFY FILE ( NAME = N'DemoDelayedDurability', SIZE = 1GB )
GO
ALTER DATABASE [DemoDelayedDurability]
MODIFY FILE ( NAME = N'DemoDelayedDurability_log', SIZE = 512MB )
GO
USE [DemoDelayedDurability]
GO
CREATE TABLE TestTable
(
ID INT IDENTITY(1,1) PRIMARY KEY CLUSTERED,
Val VARCHAR(100)
)
GO
Une fois la base et la table créées, place au test. Simple. 50 000 inserts dans la table. La première exécution en durabilité retardée désactivée, le mode historique dans SQL Server.
USE [DemoDelayedDurability]
GO
SET NOCOUNT ON
DECLARE @counter AS INT = 0
DECLARE @start DATETIME
SELECT @start = GETDATE()
WHILE (@counter < 50000)
BEGIN
BEGIN TRAN
INSERT INTO TestTable VALUES( @counter)
SET @counter = @counter + 1
COMMIT
END
SELECT DATEDIFF(MILLISECOND, @start, GETDATE() ) [Durable_Insert in msec]
SELECT * FROM sys.dm_exec_session_wait_stats
WHERE session_id = @@spid
ORDER BY wait_time_ms DESC;
Résultat : 4 secondes d’exécution, dont près de 3 secondes d’attente de type WRITELOG, 50 000 attentes, comme par hasard …
La durabilité retardée est une option de base de données qui peut prendre les valeurs Forcée ou Autorisée.
En mode Forcé, toutes les transactions se verront faire des IOs asynchrones sur le fichier LDF. En mode Autorisé, le choix est donné au développeur d’activer ou non la fonctionnalité, transaction par transaction. Car il ne faut pas perdre de vue que lorsque l’on opte pour ce mode de fonctionnement, on s’expose à une perte potentielle de données en cas de crash dans les millisecondes ou secondes qui suivent la transaction.
On opte donc pour le mode Allowed.
USE [master]
GO
ALTER DATABASE [DemoDelayedDurability]
SET DELAYED_DURABILITY = ALLOWED WITH NO_WAIT
GO
Et on rejoue le même test, attention à l’ordre COMMIT qui est modifié.
USE [DemoDelayedDurability]
GO
SET NOCOUNT ON
DECLARE @counter AS INT = 0
DECLARE @start DATETIME
SELECT @start = GETDATE()
WHILE (@counter < 50000)
BEGIN
BEGIN TRAN
INSERT INTO TestTable VALUES( @counter)
SET @counter = @counter + 1
COMMIT WITH (DELAYED_DURABILITY = ON)
END
SELECT DATEDIFF(MILLISECOND, @start, GETDATE()) [DelayedDurability_Insert in msec]
SELECT * FROM sys.dm_exec_session_wait_stats
WHERE session_id = @@spid
ORDER BY wait_time_ms DESC;
Immédiatement la différence de performance saute aux yeux, plus d’attente de type WRITELOG
Ce test a été menu sur une machine dont le disque dur est de type SSD sur protocole NVMe, donc relativement rapide.
Mais plus le sous système disque est lent, plus le phénomène est présent, et donc grève les performances de l’application.
J’ai reçu un commentaire qui m’a conduit à écrire ce post en complément de la petite vidéo, justement en lien avec des systèmes aux performances disque limitées. Ce qui suit n’est donc pas présent dans la vidéo publiée.
Afin de mettre en exergue le phénomène, j’ai choisi de mener un test similaire (sur 10000 itérations seulement) sur Azure SQL Edge, mon SQL Server qui s’exécute dans un conteneur Docker sur un Raspberry Pi (on cumule donc les « problèmes »). L’installation se passait ici.
La création de la base et de la table sont strictement identiques. On exécute le premier test, durabilité retardé désactivée.
Plus d’une minute ont été nécessaires à l’exécution des 10 000 itérations d’insert. On voit les limites d’une carte SD, même de bonne facture. Notez au passage l’attente de type PREEMPTIVE_OS_FLUSHFILEBUFFERS, apparue avec SQL Server 2017 pour les environnements Linux pour marquer effectivement le fait que l’on force cette écriture synchrone sur disque.
A présent un test avec durabilité retardé. Le constat est sans appel, moins de 5 secondes.
Il n’y a plus d’attente de type WRITELOG. Problème « résolu ».
Et donc, le commentaire reçu faisait état de problème similaire, des insertions multiples, mais il n’était pas possible de tolérer une perte de données, et donc l’obligation de conserver une durabilité immédiate.
Alors que faire ? Il ne reste pas grand-chose dans la botte du DBA. Peut être une revue de code afin de revoir la notion de transaction. Car le Flush des LOG Blocks sur disque s’effectue aussi en liaison avec le commit, donc une multitude de « petites » transactions va provoquer plus de « petits » IOs, compliqués à gérer pour le système, alors que si l’on déplace la transaction pour englober la boule, dans notre exemple, et donc exécuter l’ensemble des inserts dans UNE SEULE transaction, alors, le temps d’exécution n’est pas ridicule, loin de là.
L’exemple montre l’exécution en durabilité retardée, mais en positionnant e paramètre à OFF, le temps d’exécution est quasi similaire, avec … 1 seule attente de type WRITELOG. Logique mon cher Watson !
Cette « technique » d’optimisation est assez fréquente pour des bases hébergées sur SQL Azure, mais reste d’actualité pour tous les autres systèmes …
Comprendre le fonctionnement de SQL Server est important si vous souhaitez optimiser les performances de votre application. Si vous souhaitez une formation, n’hésitez pas à me contacter.
Suite à l’article sur Azure SQL Edge, j’ai reçu plusieurs messages demandant s’il était possible d’installer Azure SQL Edge, en fait une édition pouvant évoluer sur plateforme ARM, directement sur le Raspberry Pi sans passer par la couche IoT Hub Microsoft.
La réponse est OUI.
Je ne vais pas détailler ici l’installation d’un OS sur une carte SD à destination du Raspberry Pi. J’ai opté pour une distribution Ubuntu 20.04 qui fonctionne particulièrement bien avec le Pi4 8GB qui me servira pour ce test.
Une fois l’écriture de l’image Ubuntu sur la carte SD via Win32Diskimager (ou Rufus si vous préférez ce dernier), je procède simplement au renommage de mon OS, suivi d’une mise à jour.
Il est amusant de constater à quel point les mots clé employés dans le titre d’un post conditionnent le nombre de vues. Je ne cours pas après les followers, vous avez pu constater que je ne suis pas vraiment un grand adepte des réseaux sociaux, mais je regarde quand même les chiffres pour comprendre quelles sont vos préoccupations. Et donc proposer des articles en lien avec vos centres d’intérêt, plutôt que de disserter sur les méthodes d’irrigation du riz en Chine pendant la dynastie Ming (1368-1644 pour les curieux), ou bien sur les premières traces de sa domestication en -9000. Merci Wikipédia !
Bref. Je souhaitais revenir aujourd’hui sur un problème rencontré il y a quelques mois par une société qui a, par la suite, souhaité être conseillé de manière régulière. Si vous avez eu l’occasion de suivre une de mes formations liées à l’administration SQL Server, ou bien à la haute disponibilité, ou encore relative au dépannage de SQL Server, vous avez peut être remarqué mon manque total de confiance dans le matériel, principalement les baies de disques. Malgré tous les efforts fait par les déférents constructeurs relayés par les revendeurs à grand renfort de formations voyages, je n’y arrive pas. Impossible de faire confiance. Et je ne cible personne en particulier. Après 22 ans passés a faire du SQL Server, j’ai eu l’occasion de croiser bon nombre de modèles de baies, de différents fabriquant. Aucun n’a pu me faire changer d’avis. Non, désolé.
Alors, pas pitié, ne stockez JAMAIS, JAMAIS, JAMAISvos sauvegardes de bases de données sur la même baie de disque que vos données.
Des exemples, j’en ai … trop malheureusement. Et cela s’est accentué depuis la généralisation de la virtualisation. Il est tellement simple de créer un volume / disque supplémentaire pour une machine virtuelle sur le même datastore … Des pannes totales, comprenez par là, impossibilité de lire ou d’écrire quoi que ce soit sur la baie de disque, j’en ai vu. Ce qui met à mal bon nombre de stratégie basée sur la restauration des derniers backups. En effet, si vous n’avez qu’une seule baie, impossible de relancer ou de recréer des VMs. De même, si vous pensez restaurez vos données sur des VM Azure par exemple, encore une fois, cela ne sera pas pas possible.
Pensez donc à la disponibilité voire la haute disponibilité de vos sauvegardes. Gardez toujours en mémoire le bon vieil acronyme 3-2-1:
3 copies des données : les données de production et 2 copies
2 supports différents : attention, je ne parle pas de 2 volumes sur une même baie mais bien de 2 baies de disque distinctes, si possible de marque différentes pour éviter tout risque de problèmes sur les contrôleurs ( non, ça n’arrive jamais lors d’opération de mise à jour, jamais …)
1 copie à l’extérieur : le gage de pouvoir effectuer une restaure en cas de non disponibilité de votre Datacenter.
Oui, tous ces points sont importants. Le dernier, la copie extériorisée est plus simple à implémenter que par le passé grâce aux différents services en ligne offerts par Microsoft, Amazon ou Google, ainsi que les éditeurs de solutions de sauvegarde / archivage. Auparavant, OK, on pouvait sortir un bande tous les X jours par exemple. Mais qui pensait à garder également à l’extérieur un exemplaire du matériel / logiciel nécessaire à la restauration ? Avoir une bande et devoir patienter 4 à 6 semaines pour réceptionner un lecteur qui aurait été détruit dans l’incendie de la salle technique est tout bonnement impensable, et réellement préjudiciable pour l’entreprise.
J’ai déplacé le débat niveau matériel, mais on peut également étendre la discussion aux sauvegardes SQL Server. Vous effectuez les test d’intégrité sur vos base de manière quotidienne, avant la sauvegarde ? Est-ce que vous testez régulièrement vos backups ? A J+1, mais aussi à J+7 ou J+30 ? Quelles sont vos contraintes légales en matière de rétention ? Si on vous demande 1 an, assurez vous très régulièrement que vous êtes en mesure de lire et de restaurer durant toute la période. Une corruption disque peut arriver à n’importe quel moment, ce n’est pas parce qu’un backup s’est terminé correctement que son utilisation sera possible plus tard …
Il n’est pas une semaine sans que l’on relate l’histoire d’une entreprise traitant d’une attaque de Ransomware. Encore une fois, mixer les technologies peut permettre de limiter les dégâts. J’ai en stock une expérience d’un client dont le Ransomware a affecté la production mais également le NAS hébergeant les sauvegardes. Bref, posez vous une bonne journée pour évaluer les différentes scénarii et planifier un DRP / PRA.
Autre mythe que je voudrais mettre à bas également : les sauvegardes restent OBLIGATOIRES même si vous disposez d’une solution de haute disponibilité SQL Server telles que le cluster de basculement ou les groupes de disponibilité. Je ne compte même plus le nombre de bases n’ayant pas fait l’objet de sauvegardes durant plusieurs années … No comment.
Abordons la gestion des sauvegardes pour SQL Azure, dont vous pouvez vous inspirer pour votre stratégie. Le premier point à retenir, c’est que … vous n’avez rien à faire ! SQL Azure est un service PaaS, donc la sauvegarde est à la charge du hosteur, Microsoft. D’un point de vue stratégie de sauvegarde, du classique. La fréquence des sauvegardes prévoit un backup full toutes les semaines, un backup différentiel toutes les 12 ou 24 heures et une sauvegarde du journal des transactions toutes les 5 à 10 minutes (basé entre autres sur l’activité de votre base, l’idée étant de limiter au maximum la croissance du fichier journal). Rien d’extraordinaire jusqu’à présent, il y a fort à parier que votre stratégie est très similaire à celle employée sur Azure SQL Databases et sur les instances managées.
La rétention par défaut des sauvegardes SQL Azure est de 7 jours. Vous pouvez étendre la période à 35 jours … Voire opter pour une politique LTR (Long Term Retention) qui conserve vos sauvegardes jusqu’à 10 ans.
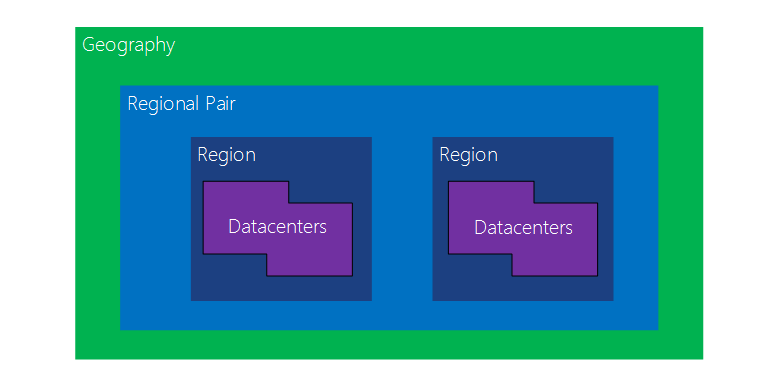
Pour être raccord avec le thèse de ce billet, on peut s’intéresser à la redondance du stockage. Par défaut, ces sauvegardes sont hébergées sur un stockage redondant type RA-GRS. Si vous êtes novices en matière de stockage de type Blobs sur Azure, je vous renvoie à cette page qui vous donne les différents types de stockages. Mais globalement, GRS stipule que le stockage est redondant dans la région. Une région étant un ensemble de datacenters interconnectés en faible latence, disposant chacun d’alimentation électrique, d’accès internet et de climatisation distinctes.
Votre Backup posé sur un tel stockage sera répliqué de manière synchrone 3 fois à l’intérieur de la région primaire (stockage LRS : Local Redundant Storage) et ensuite copié de manière asynchrone vers la région pairée (France Central <-> France Sud). les lettres RA signifie simplement Read-Access, vous pouvez lire les backups sur la région pairée en cas de perte totale d’une région Azure. La distance entre les zones étant de quelques centaines de kilomètres il y a peu de chances que les 2 zones soient indisponibles en même temps. Pour les adeptes des « Nines » pour évaluer la disponibilité, la durabilité des objets sur le stockage Azure est de 99,99999999999999 % (16 neufs) sur 1 an et d’au moins 99.99% en ce qui concerne la disponibilité.
La copie étant asynchrone entre la région principale et la région secondaire, le RPO sera donc plus important que si votre région primaire est encore disponible. Mais vous aurez au moins la possibilité de repartir sur un backup … Cela se passe dans le portail Azure, dans l’assistant de création d’une base de données. Vous avez la possibilité de créer une base de données vierge, mais aussi de restaurer une sauvegarde antérieure.
La date et heure (UTC) accolée à chaque sauvegarde correspond à la dernière copie asynchrone sur la région pairée. Ces sauvegardes sont accessibles à un serveur qui n’appartient pas forcément à la région primaire ni à la région secondaire de vos backups. Vous pouvez donc restaurer sur un serveur localisé partout ailleurs dans le monde.
Si par contre vous souhaitez un point de restauration plus précis, dans ce cas il est obligatoire d’utiliser le stockage localement redondant (LRS) et donc d’utiliser l’assistant de restauration d’une base dans le portail.
Vous avez donc à présent conscience de l’infrastructure mise en œuvre par Microsoft pour la conservation des sauvegardes des bases de données et la disponibilité de ces sauvegardes. J’entends les remarques relatant le fait que Microsoft n’a pas forcément les mêmes contraintes, probablement bien plus élevées que la très grande majorité des sociétés, mais il reste que le modèle en place est hautement disponible. Il est peut être temps de repenser votre stockage pour augmenter la disponibilité de vos sauvegardes. Je n’ai pas réussi à remettre la main (mais je compte sur vous …) sur une étude relatant les faillites de sociétés après un désastre informatique. J’ai des chiffres en tête, 80% de faillites dans les 5 ans à venir, mais j’aurais préféré les résultats de l’étude. Le chiffre peut faire peur, et doit faire peur. Il est du rôle du DBA de s’assurer que les données de l’ERP, du site Web de vente en ligne, de la comptabilité seront accessibles en cas de problème …
Je n’ai rien à y gagner, je ne vais pas vous vendre une baie de disque, ni du stockage cloud et encore moins une solution de sauvegarde/archivage, mais je voudrais juste éviter d’avoir à dire une nouvelle fois « désolé, là, je ne peux rien faire pour vous » car votre baie est HS, ou bien les données et les sauvegardes étaient sur la même VM cryptolockée. Volontairement, je n’ai pas abordé la notion de sauvegarde de VM. Je ne suis pas fan de la solution, au vu de tous les problèmes que cela peut engendrer.